
Autores : Giulia Menichetti , Ph.D. , Albert-László Barabási , Ph.D. y Joseph Loscalzo , MD, Ph.D. el 7 de mayo de 2025
N Engl J Med 2025 ; 392 : 1836 – 1845DOI: 10.1056/NEJMra2413243 VOL. 392 NÚM. 18
Gráfico interactivo

La complejidad química de los alimentos y sus implicaciones terapéuticas La mala nutrición es una de las principales causas de enfermedad en Estados Unidos, contribuye a más de medio millón de muertes al año<sup> 1,2</sup> y afecta a la mitad de los adultos estadounidenses que padecen una o más enfermedades no transmisibles prevenibles, como enfermedades cardiovasculares, hipertensión, diabetes mellitus tipo 2, cáncer y mala salud ósea<sup> 3</sup> Además de aumentar el riesgo de enfermedad, la mala nutrición tiene amplios efectos sociales, elevando los costos de la atención médica y disminuyendo la productividad, con gastos tan solo por obesidad que alcanzan los 173 mil millones de dólares anuales<sup> 2 </sup>. En cambio, adoptar una dieta y un estilo de vida saludables puede contrarrestar significativamente incluso una fuerte predisposición genética a la enfermedad coronaria y reducir el riesgo relativo en casi un 50 %<sup> 4</sup>La creciente evidencia destaca aún más la importancia de la calidad de la dieta en la prevención de enfermedades, en particular en medio del aumento global de cánceres de aparición temprana, una prioridad de investigación emergente identificada por el Instituto Nacional del Cáncer. 5 De hecho, desde la década de 1990, la incidencia de cáncer entre adultos menores de 50 años ha aumentado en todo el mundo, a pesar de que las tasas de cáncer hereditario se mantienen sin cambios, un hallazgo que subraya la influencia de factores ambientales y de estilo de vida. 6
Las exposiciones en la primera infancia han cambiado notablemente en las últimas décadas y reflejan tendencias hacia el sobrepeso, la obesidad y las dietas de estilo occidental, incluso entre niños y adolescentes. 6Estos patrones epidemiológicos resaltan las limitaciones de centrarse únicamente en la genética. Si bien el Proyecto Genoma Humano amplió considerablemente nuestra comprensión de las contribuciones hereditarias a las enfermedades, los genes parecen explicar aproximadamente el 10% del riesgo de enfermedad, y el resto está determinado en gran medida por factores ambientales y dietéticos. 7 Para aprovechar la riqueza de descubrimientos del Proyecto Genoma Humano, debemos reconocer que los alimentos no solo son una fuente de calorías y vitaminas, sino que también contienen una amplia gama de sustancias químicas con implicaciones para la salud que van más allá de las conocidas actualmente. De hecho, las sustancias químicas de los alimentos pueden regular la actividad de las proteínas humanas y microbianas, lo que acerca los estudios nutricionales a la resolución típica de la investigación ómica. Llenar esta brecha fundamental de conocimiento nos ayudará a redefinir cómo medimos la calidad de la dieta y a mejorar la precisión de las intervenciones dietéticas. A medida que avanza la iniciativa «La Comida Es Medicina», 8 que promete una mejor salud a través de una alimentación nutritiva, se vuelve crucial mapear las moléculas de los alimentos e identificar con precisión los mecanismos que contribuyen a nuestro bienestar. En este artículo, revisamos la excepcional complejidad química de nuestra dieta y analizamos sus implicaciones para la salud. Nuestro análisis se basa en la biblioteca de Materia Oscura Nutricional (NDM), una base de datos seleccionada y armonizada, creada por nuestro grupo, que cataloga miles de sustancias químicas alimentarias distintas, junto con sus identificadores estructurales únicos, propiedades fisicoquímicas y anotaciones sobre los alimentos. A partir de diversos repositorios biológicos como PubChem, DrugBank y BRENDA (Base de Datos de Enzimas de Braunschweig), la biblioteca NDM proporciona una perspectiva actualizada del vasto panorama bioquímico de los alimentos y las nuevas oportunidades para explorar nuevas terapias. La evidencia sugiere que más de 139 000 sustancias químicas presentes en los alimentos modulan conjuntamente un gran número de proteínas humanas. Aproximadamente 2000 de estas moléculas alimentarias se utilizan actualmente como fármacos. Por lo tanto, existe una enorme reserva de sustancias químicas con funciones subcelulares aún desconocidas, y esta reserva podría servir como punto de partida para futuras terapias. Por último, también exploramos los obstáculos actuales para abordar esta enorme brecha en nuestra comprensión de la dieta y las posibles vías para superarlos ( Figura 1 ).

Taxonomía molecular de los alimentos
Los nutrientes, definidos como las sustancias químicas esenciales para mantener las funciones básicas del cuerpo, se clasifican típicamente en seis clases principales: carbohidratos, lípidos, proteínas, vitaminas, minerales y agua. 13 Las bases de datos nacionales de alimentos, como la del Departamento de Agricultura de los Estados Unidos (USDA), se centran principalmente en estas clases químicas, proporcionando información detallada sobre hasta 150 micronutrientes y macronutrientes esenciales, principalmente vinculados a la ingesta de energía y el metabolismo. Si bien este panel nutricional básico ha moldeado durante mucho tiempo nuestra comprensión de los alimentos, sigue siendo limitado a la hora de capturar la riqueza química completa dentro de los ingredientes básicos de las dietas humanas. De hecho, las materias primas de los alimentos, que representan organismos que alguna vez estuvieron vivos, tienen una diversidad química excepcional. Esto es particularmente cierto para las plantas que, incapaces de usar la locomoción para escapar de los depredadores, han desarrollado extensas vías metabólicas secundarias que generan texturas, colores y olores distintivos que ahuyentan a algunos depredadores mientras atraen a otros. Estas vías metabólicas producen miles de polifenoles, terpenoides y alcaloides que no pueden ser generados por el metabolismo humano, pero que son esenciales para nuestro bienestar.
Complejidad química de los alimentos
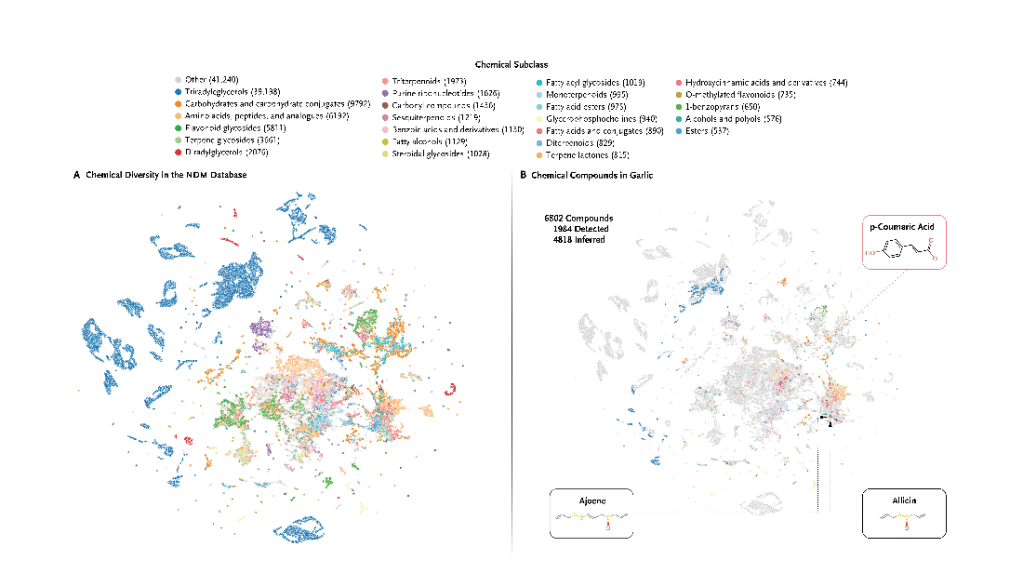
•Más de 139.000 moléculas presentes en los alimentos, denominadas “materia oscura nutricional” (NDM), encierran un potencial terapéutico inmenso y en gran medida sin explotar. •Las moléculas de los alimentos afectan a casi la mitad del proteoma humano y desempeñan un papel como moduladores amplios de los procesos biológicos. •Aproximadamente 2.000 moléculas de alimentos ya se utilizan como medicamentos, lo que pone de relieve la relevancia farmacéutica de los productos químicos alimentarios. •Las herramientas de inteligencia artificial (IA) avanzadas y los marcos de medicina en red podrían ayudar a los investigadores a decodificar la relevancia de la NDM para la salud y permitir predicciones de objetivos moleculares y mecanismos biológicos.•La falta de un mapeo sistemático de las sustancias químicas de los alimentos limita el progreso; se necesitan urgentemente financiación estratégica y enfoques escalables basados en inteligencia artificial. •El mapeo del NDM podría revolucionar la ciencia dietética y acelerar el descubrimiento de fármacos, lo que complementaría los logros del Proyecto Genoma Humano. A pesar del aumento de la inversión en investigación desde 2003 para caracterizar el contenido de moléculas pequeñas, 14-17 la gama completa de compuestos presentes en los alimentos sigue siendo en gran medida desconocida. En 2019, esta constatación nos llevó a acuñar el término «materia oscura nutricional», que destaca la gran cantidad de moléculas alimentarias que en gran medida no son rastreadas por las bases de datos de composición de alimentos ni por la investigación epidemiológica. 14,18 Desde entonces, hemos intensificado los esfuerzos para documentar sistemáticamente la presencia de moléculas pequeñas en los alimentos. Estos compuestos orgánicos de bajo peso molecular, cuya masa suele oscilar entre 50 y 1500 daltons, presentan características similares a las de los fármacos y a menudo sirven como sustratos o productos en procesos biológicos. 19Hemos catalogado 139.443 sustancias químicas en la biblioteca NDM, cada una identificada con un identificador químico internacional válido (InChIKey), distribuidas en más de 3000 alimentos comunes y 17.000 especies de la taxonomía del Centro Nacional de Información Biotecnológica. 20 La creación de este recurso requirió la agregación y desambiguación de datos de varios campos científicos, incluyendo anotaciones extraídas de una amplia gama de literatura especializada, 21 experimentos de espectrometría de masas no dirigidos, 22 y diversas bases de datos de composición. 23-25 Las predicciones genómicas y de vías contribuyeron a este esfuerzo integral. 26 La base de datos resultante proporciona identificadores químicos que vinculan las anotaciones a bibliotecas externas que van desde el Diccionario de compuestos alimentarios 24 a FooDB, 25 PhytoHub, 27 y las bases de datos del USDA, 28 por nombrar solo algunas.Los modelos de lenguaje químico como MoLFormer, 29 que representan cada molécula de alimento como un vector incrustado en un espacio de alta dimensión (768 dimensiones para MoLFormer), nos permiten visualizar las similitudes estructurales y funcionales de las moléculas de alimentos en la biblioteca NDM. Como se muestra en la Imagen 1A del gráfico interactivo , la biblioteca NDM contiene una amplia variedad de estructuras lipídicas que sirven como mensajeros intracelulares, incluyendo glicósidos terpénicos (3662), diacilgliceroles (2076), esteroides (2942) y esfingolípidos (258). El metabolismo secundario de las plantas también está bien representado, particularmente por la superclase química 30 de fenilpropanoides y policétidos (12,827), que incluye familias de compuestos conocidos como flavonoides (7624), isoflavonoides (1106), ácidos cinámicos (916), cumarinas (876), taninos (405) y estilbenos (340). Otras superclases están vinculadas al metabolismo secundario de las plantas, como los alcaloides (910), los lignanos y neolignanos (669) y los compuestos organosulfurados (547), lo que subraya la excepcional diversidad de los productos químicos que consumimos a diario.Pensemos en el ajo, un alimento básico en muchas cocinas y usado con fines medicinales durante miles de años, desde el antiguo Egipto. 31 La base de datos USDA SR Legacy enumera 69 nutrientes para el ajo crudo, pero no rastrea compuestos organosulfurados clave como la alicina 32 (responsable del aroma distintivo del ajo recién machacado) y el ajoeno, 33 ambos contribuyen a las propiedades cardioprotectoras y antimicrobianas del ajo. 34-37 Además, la base de datos no incluye el ácido p-cumárico, 38 un ácido hidroxicinámico que pertenece a la amplia clase de polifenoles y es conocido por sus efectos protectores contra la carcinogénesis y la inflamación. 39,40 Como hemos demostrado recientemente, 14 estos tres compuestos son solo una pequeña fracción de las 6802 pequeñas moléculas documentadas en el ajo crudo (Imagen 1B en el gráfico interactivo ), muchas de las cuales son metabolitos secundarios que sirven como defensa química de la planta contra el clima extremo y los depredadores.

De las moléculas de alimentos a los fármacos
Los 150 componentes nutricionales que rastrea el USDA son esenciales para nuestra salud; sirven como fuentes de energía, proporcionan aminoácidos esenciales para el crecimiento y la reparación, y regulan la actividad enzimática actuando como cofactores o cosustratos. En este contexto, se podría suponer razonablemente que el amplio espectro de moléculas catalogadas en la biblioteca NDM no forma parte del enfoque de nutrientes esenciales del USDA, por la sencilla razón de que estas moléculas no son componentes centrales del metabolismo humano y, por lo tanto, se consideran inertes. Sin embargo, en realidad, muchas de estas moléculas tienen implicaciones bien documentadas para la salud. Por ejemplo, en lugar de interactuar directamente con las vías metabólicas centrales, muchos polifenoles, que se absorben de la dieta en diferentes grados, se unen a proteínas humanas específicas, modulan la composición de la microbiota intestinal y regulan una amplia gama de procesos subcelulares. En otras palabras, en cuanto a los mecanismos de acción, las moléculas NDM podrían estar más cerca de los fármacos que de las fuentes de energía estudiadas convencionalmente por los bioquímicos nutricionales. Muchos medicamentos aprobados son sustancias químicas NDM. El origen de la aspirina, por supuesto, se remonta al ácido salicílico presente en la corteza de sauce y en ciertas frutas y verduras. 41 De igual manera, la lovastatina está relacionada con compuestos presentes en el arroz de levadura roja, un alimento básico en algunas culturas, 42 y la quinina, un remedio tradicional para la malaria, se deriva de la corteza del árbol de quina y todavía se utiliza en el agua tónica. 43 Estos no son ejemplos aislados. De los 8219 medicamentos de moléculas pequeñas reportados en DrugBank con dianas conocidas, 44 el 22,55 % también aparece en la biblioteca NDM, lo que implica que son moléculas presentes en ingredientes naturales que consumimos. En la Imagen 2A del gráfico interactivo , las incrustaciones moleculares (o la conversión de estructuras moleculares en representaciones vectoriales, como en MoLFormer) muestran cómo las moléculas de la familia actual de fármacos se agrupan junto a compuestos naturales documentados en la biblioteca NDM. Tomemos, por ejemplo, el ácido rosmarínico, un polifenol reconocido por sus efectos antitrombóticos ejercidos por la unión a proteínas de señalización implicadas en la activación plaquetaria. 45 Este compuesto, actualmente pasado por alto por el USDA, se alinea estrechamente con el clopidogrel, un fármaco antiplaquetario sintético, en el espacio de incrustación; como se muestra en la Imagen 2A del gráfico interactivo , los compuestos farmacológicos tienden a agruparse en una región distinta del espacio NDM, particularmente cerca de aminoácidos, péptidos y derivados del ácido benzoico, que predominantemente tienen propiedades hidrófilas. Virtualmente ningún área de este espacio relacionado con los fármacos está intacta por las moléculas de los alimentos, lo que refleja el hecho de que muchos fármacos actuales se han inspirado en compuestos naturales. Sin embargo, actualmente, solo el 1,33% de los compuestos de la biblioteca NDM se aprovechan con fines farmacéuticos, lo que sugiere un potencial vasto y sin explotar dentro del panorama químico más amplio de los alimentos.La tendencia de las moléculas de fármacos a agruparse en zonas específicas de la biblioteca NDM puede atribuirse en parte a los métodos de diseño de fármacos. Uno de estos métodos, conocido como «química de imitación» (me-too chemistry), implica modificaciones iterativas de compuestos existentes que a menudo se adaptan a dianas proteicas precisas, lo que limita la diversidad de estructuras químicas utilizadas en el diseño de fármacos. Por ejemplo, los 115 antagonistas adrenérgicos reportados en DrugBank se concentran en una región pequeña y localizada de la biblioteca NDM, lo que indica no solo su origen en los alimentos, sino también su estrecho espectro químico. De hecho, algunos de los primeros antagonistas adrenérgicos se derivaron de fuentes naturales, en particular alcaloides vegetales, como la reserpina, un alcaloide extraído de la planta Rauwolfia serpentina , y los alcaloides del cornezuelo, derivados del hongo Claviceps purpurea ( que, por supuesto, pueden servir como antagonistas y agonistas adrenérgicos). Sin embargo, la mayoría de los antagonistas adrenérgicos modernos (96 de 115) son sintéticos, ya que los avances en química orgánica y farmacología han permitido el diseño de nuevas moléculas que bloquean específicamente los receptores adrenérgicos alfa o beta y sus subtipos. Aun así, estas nuevas moléculas conservan una química similar a las moléculas naturales que las inspiraron y, por lo tanto, se agrupan en la misma vecindad de la biblioteca NDM (Imagen 2B del gráfico interactivo ).A diferencia de los fármacos, las moléculas de los alimentos, moldeadas por millones de años de evolución, tienen una mayor diversidad química, lo que les permite interactuar con una gama más amplia de objetivos proteicos. Estos compuestos alimenticios evolucionaron en ecosistemas dinámicos, donde variaron en concentración y compitieron por diferentes objetivos biológicos. En consecuencia, las moléculas de los alimentos a menudo proporcionan andamiajes químicos que están optimizados para la unión a proteínas 49 pero también tienen una amplia gama de estructuras y características. Un ejemplo se muestra en la Imagen 2C en el gráfico interactivo , donde destacamos 12,889 polifenoles, 21 moléculas que tienen múltiples beneficios para la salud, como la actividad antioxidante o prooxidante, que logran uniéndose a proteínas, modulando las vías de transducción de señales a través de la señalización entre reinos, 49,50 e interactuando con la microbiota intestinal. Como resultado, no se limitan a un vecindario estrecho de la biblioteca NDM, sino que se extienden a través de un área amplia del espacio químico. En conjunto, los ejemplos de la Imagen 2 del gráfico interactivo ilustran la amplia diversidad química inherente a las moléculas de los alimentos, en comparación con la diversidad mucho menor de los fármacos aprobados. Esta diferencia resalta el potencial terapéutico sin explotar de una recopilación exhaustiva de pequeñas moléculas presentes en los alimentos. Como se explica más adelante, este recurso no solo enriquecería nuestra comprensión de las implicaciones de la dieta para la salud, sino que también enriquecería considerablemente el panorama de la investigación en farmacología de sistemas.
Proteínas y NDM
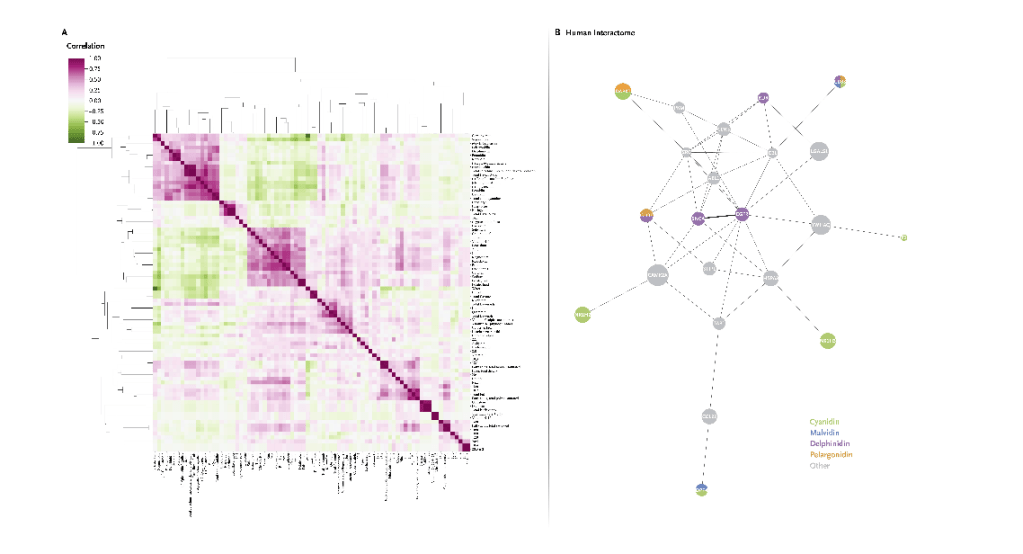
La amplia diversidad química de las moléculas de los alimentos y su función reguladora no metabólica plantean la pregunta: ¿qué parte del proteoma modulan? Este problema se representa en la Imagen 3 del gráfico interactivo , donde utilizamos node2vec para visualizar el interactoma humano 51,52 , un mapa subcelular que cataloga 354.659 interacciones físicas entre 18.659 proteínas humanas. Dado el gran número de interacciones, es imposible mostrar la red completa de forma legible. En cambio, el diseño de la figura refleja la red subyacente, con las proteínas que interactúan colocadas más cerca unas de otras que las proteínas que no interactúan. Lo que es más importante, la figura muestra todos los objetivos proteicos que tienen anotaciones de unión conocidas y validadas experimentalmente con moléculas pequeñas en la biblioteca NDM, 44 lo que indica que aproximadamente la mitad del interactoma (8997 proteínas) es el objetivo de las moléculas de los alimentos. Dado que solo el 6,45 % de las moléculas alimentarias de la biblioteca NDM presentan al menos una anotación de unión validada experimentalmente, es probable que la fracción real de proteínas moduladas por moléculas alimentarias sea mucho mayor. Sin embargo, existe una diferencia fundamental entre el papel de los fármacos y el de las moléculas alimentarias: en un momento dado, solo unas pocas proteínas son moduladas sustancialmente por los fármacos administrados en respuesta a una enfermedad. Por el contrario, las moléculas alimentarias influyen en la actividad de gran parte del proteoma a lo largo de la vida, y la variabilidad individual depende de las decisiones dietéticas (cantidad de alimento ingerido, momento de la ingestión, composición de la matriz, otros alimentos coingeridos, etc.).Aunque los fármacos y los compuestos dietéticos comparten características como moléculas pequeñas, los objetivos proteicos de los fármacos son altamente específicos, ya que son seleccionados o diseñados para limitar las asociaciones y mitigar los posibles efectos secundarios. Los compuestos naturales en los alimentos tienen mayor diversidad estructural y promiscuidad, lo que les permite unirse a una amplia gama de objetivos. Para abordar estos desafíos, recurrimos a la medicina de redes, 52,53 que define las enfermedades como cambios localizados en las redes de interacción subcelular. Identificamos el efecto relativo de un fármaco o una molécula de alimento en el interactoma midiendo el tamaño del subgrafo más grande de proteínas interactuantes diana por la misma sustancia química. 54,55 Aquí, nos centramos en las moléculas anotadas simultáneamente tanto por la biblioteca NDM como por DrugBank (1853 moléculas), ofreciendo una evaluación más imparcial al informar la bioactividad de las moléculas de alimentos que han recibido tanta atención científica como la prestada a las moléculas de los fármacos. Encontramos que, en promedio, los subgrafos generados por los objetivos de las moléculas de alimentos conectan 24,44 objetivos. Esto es 2,89 veces mayor que el número de proteínas interactuantes diana de las moléculas encontradas en DrugBank que no tienen su origen en los alimentos, que es de tan solo 8,47 (valor P de Mann-Whitney: 3,35 × 10 −41 ; tamaño del efecto: 0,14). La mayor vecindad del interactoma modulada por moléculas individuales de alimentos refleja su efecto molecular más amplio, que no puede interpretarse fácilmente a través del estrecho enfoque que se suele aplicar en el diseño de fármacos. Las moléculas de alimentos actúan como moduladores promiscuos de las redes moleculares celulares, influyendo simultáneamente en múltiples procesos y vías.Además, las moléculas de los alimentos, a diferencia de los fármacos, entran en contacto con el interactoma no de forma aislada, sino junto con otras moléculas alimentarias que suelen ser interdependientes. Estas interdependencias se muestran en la Imagen 4A del gráfico interactivo , que muestra la matriz de correlación de Spearman de las concentraciones químicas medidas para 108 frutas y verduras crudas con concentraciones catalogadas por el USDA en múltiples alimentos. Observamos grupos distintos de compuestos altamente correlacionados que a menudo reflejan vías compartidas en el metabolismo vegetal. Por ejemplo, la vitamina K 1 y la luteína, que tienen una diferencia de al menos un orden de magnitud en sus concentraciones promedio, 12 muestran una fuerte correlación debido a su vía biosintética compartida y a su precursor común, el pirofosfato de geranilgeranilo. Por el contrario, la delfinidina, una antocianidina, pertenece a un grupo separado, lo que indica la ausencia de una vía biosintética compartida. Estos hallazgos sugieren que muchas moléculas alimentarias producidas conjuntamente por el metabolismo de un organismo comparten características estructurales y funcionales, y a menudo se dirigen a las mismas áreas del interactoma humano. Las antocianidinas y las antocianinas, por ejemplo, difieren únicamente en la unión de las moléculas de azúcar. Su presencia en los alimentos muestra una fuerte correlación de Spearman, que oscila entre 0,4839 y 0,7283, y también modulan una vecindad común del interactoma mediante la acción de 10 dianas proteicas compartidas (Imagen 4 del gráfico interactivo ).
El lenguaje de la comida
La notable complejidad química de nuestra dieta queda ilustrada por las 139.443 moléculas documentadas en los alimentos, una cifra que seguirá aumentando con la investigación. Si bien la gran mayoría de estas moléculas se detectó en uno o, como máximo, en unos pocos ingredientes alimentarios, es probable que estén presentes en múltiples alimentos. Por lo tanto, para comprender plenamente la dieta y sus posibles implicaciones para la salud, necesitamos completar la matriz química de los alimentos, actualmente incompleta, ofreciendo información precisa sobre cuáles de estos compuestos bioquímicos se encuentran en ingredientes alimentarios específicos, junto con sus concentraciones. Aunque solo estamos al comienzo de este viaje, la Iniciativa de la Tabla Periódica de los Alimentos (PTFI; https://foodperiodictable.org/ ) 56 —liderada por la Asociación Estadounidense del Corazón 57 — ha dado un primer paso importante al esforzarse por estandarizar la “foodómica” y caracterizar exhaustivamente la composición química de los alimentos, utilizando técnicas “ómicas” modernas (véase el Apéndice complementario , disponible con el texto completo de este artículo en NEJM.org). Sin embargo, al 15 de agosto de 2024, los datos estaban disponibles solo para 328 de los 1650 alimentos esperados. Además, mientras que el conjunto de datos de referencia de la PTFI cuantifica 165 clases químicas amplias o compuestos individuales —que se superponen sustancialmente con el panel de nutrientes del USDA—, el conjunto de datos de descubrimiento de la PTFI, que implica el uso de metabolómica no dirigida, comprende 18 000 compuestos. Sin embargo, solo 462 de estos compuestos están caracterizados estructuralmente. El resto se define únicamente por fórmulas moleculares, lo que limita nuestra capacidad para realizar estudios mecanísticos precisos y caracterizar la bioactividad de estas moléculas. La integración del PTFI con la biblioteca NDM arrojó tan solo 41 compuestos adicionales con claves InChI completamente resueltas, lo que indica que la base de datos captura en gran medida sustancias previamente documentadas. Este contraste deja claro que establecer un proceso de foodómica reproducible y estandarizado difiere notablemente de explorar el NDM en toda su extensión. Dadas las limitaciones de tiempo y escalabilidad de las plataformas experimentales actuales, la medida inmediata más efectiva podría ser consolidar y racionalizar los datos existentes. Estos esfuerzos pueden orientar las tareas posteriores, incluyendo la priorización de la validación experimental y la resolución más rápida de lagunas críticas de conocimiento. Podemos seguir un camino alternativo y lograr una mayor escalabilidad aprovechando los rápidos avances en inteligencia artificial (IA). Como hemos argumentado en otras publicaciones, la integración de la información recopilada en repositorios masivos de espectrometría de masas sobre diferentes ingredientes alimentarios con las relaciones filogenéticas entre especies ofrece una vía para mapear la matriz química de los alimentos y obtener una descripción precisa de cuáles de estas moléculas se encuentran en cada ingrediente. Lograr este objetivo sigue siendo improbable a corto plazo, pero si el proyecto se completa, su impacto en nuestra comprensión de la dieta y la biología (o patobiología) será comparable al efecto del Proyecto Genoma Humano en la medicina.No necesitamos la matriz química completa de ingredientes para empezar a descubrir el potencial del NDM. De hecho, las 139.443 moléculas ya documentadas en la biblioteca de NDM son generalmente seguras cuando se consumen en porciones regulares en concentraciones presentes de forma natural en los alimentos, y muchas de ellas tienen dianas proteicas humanas conocidas capaces de modular procesos subcelulares específicos. En conjunto, este espacio químico natural es aproximadamente diez veces mayor que el conjunto actual de fármacos aprobados y experimentales. Si la investigación clínica confirma el valor terapéutico de alguno de estos compuestos, su perfil de seguridad establecido en niveles dietéticos estándar podría permitir su uso como suplementos y, potencialmente, evitar la necesidad de los largos y costosos ensayos de seguridad necesarios para la aprobación de la Administración de Alimentos y Medicamentos (FDA). Además, el conocimiento de las dianas de las moléculas de NDM con mecanismos de acción validados puede ayudar a identificar posibles nuevas dianas para intervenciones terapéuticas, acelerando la identificación de dianas, un obstáculo en el descubrimiento de fármacos. Las moléculas de NDM con dianas conocidas y potencial terapéutico también pueden modificarse para lograr una unión más fuerte y así dar lugar a nuevas clases de fármacos.
¿Cuáles son los desafíos actuales para activar el excepcional conjunto de conocimientos que ofrece la biblioteca NDM?
En primer lugar, necesitamos conocer las dianas proteicas de cada molécula alimentaria. En segundo lugar, necesitamos predecir su posible efecto terapéutico, es decir, qué procesos celulares modulan y cuál es su mecanismo de acción. Los recientes avances en IA y medicina en red ofrecen las herramientas para completar este paso clave para comprender el posible efecto terapéutico de las moléculas alimentarias es comprender dónde se unen. Dado que solo se dispone de anotaciones de unión validadas experimentalmente para el 6,45 % de las moléculas de NDM, necesitamos predecir con fiabilidad las interacciones de unión de las moléculas pequeñas derivadas de alimentos con proteínas humanas y microbianas 58,59 ; esto último nos permitiría comprender cómo las moléculas alimentarias modulan el microbioma más allá de los datos de estudios estándar sobre la abundancia relativa de especies microbianas.
Para abordar estos problemas, resulta imperativo invertir en modelos de IA capaces de predecir interacciones de unión con precisión y eficiencia a gran escala. Sin embargo, se ha demostrado que los modelos de IA de vanguardia para el descubrimiento de fármacos son propensos a un aprendizaje abreviado, 60,61 en el que el modelo no comprende plenamente los principios de la unión ligando-proteína y tiene dificultades para generalizarse a nuevas moléculas. Por lo tanto, para mejorar la capacidad de generalización de estos modelos para moléculas alimentarias, los esfuerzos futuros deben centrarse en estrategias de entrenamiento que fomenten una comprensión más profunda de la unión ligando-proteína, como la incorporación de conjuntos de datos de entrenamiento más diversos, el perfeccionamiento de las arquitecturas de los modelos, el diseño de una validación cruzada más compleja y la validación rigurosa de las predicciones con ensayos experimentales. Este desarrollo debería ocurrir en paralelo con el mapeo a gran escala de la composición molecular de los alimentos para proporcionar un contexto biológico significativo para cada molécula identificada, revelar interdependencias y acelerar nuestra comprensión de sus efectos sobre la salud. Alpha Fold 3 62 es uno de los avances más prometedores en este campo, pero su escalabilidad y precisión en la predicción de interacciones para más de 139.000 moléculas pequeñas en alimentos y más de 18.000 proteínas en el interactoma humano aún no se han probado. En última instancia, las herramientas de IA deberán combinarse con ensayos experimentales para probar las predicciones y lograr la precisión y claridad que proporciona la combinación de ensayos de purificación por espectrometría de masas y de dos híbridos de levadura, que han ayudado a mapear la red de interacción de proteínas. 63Para descubrir los mecanismos de acción de las moléculas pequeñas, podemos recurrir a la medicina de redes, que ha contribuido al desarrollo de predicciones refutables que pueden validarse experimentalmente. Consideremos, por ejemplo, el ácido rosmarínico (Imagen 2A del gráfico interactivo ), que actúa sobre FYN junto con PDE4D, CD36 y APP, proteínas de enfermedades vasculares asociadas con la función plaquetaria.<sup> 14</sup> El componente conectado que estas dianas forman dentro del interactoma humano sugiere que la molécula alimentaria podría afectar la formación de trombos plaquetarios en enfermedades vasculares. Experimentos in vitro han confirmado esta predicción y demostrado que el ácido rosmarínico inhibe la agregación plaquetaria mediada por colágeno y la secreción de gránulos α al inhibir la fosforilación de la tirosina proteica mediante su interacción con FYN. <sup>19</sup>En conjunto, los avances en la predicción basada en IA de las dianas de las moléculas NDM, junto con las herramientas de la medicina en red, nos permiten aprovechar el excepcional conocimiento de la biblioteca NDM. En última instancia, esta estrategia podría permitirnos identificar moléculas alimentarias con un efecto terapéutico directo en enfermedades específicas y constituir el punto de partida para el desarrollo de nuevos fármacos y terapias.
Conclusiones
La secuenciación del genoma humano ha revolucionado la biología al ofrecer una plataforma para explorar las variaciones genómicas, así como para comprender cómo estas variaciones conducen a enfermedades. Esta información es esencial, pero no suficiente para comprender las enfermedades humanas, como lo ilustra el hecho de que los efectos genéticos representan solo el 10% de las incidencias de enfermedades; la mayor parte de las incidencias restantes se pueden vincular a factores ambientales y dietéticos. 7 Para aprovechar al máximo el potencial de la dieta en la mejora de la salud y la longevidad, debemos caracterizar el vasto repertorio molecular de los alimentos. El enfoque que describimos —identificar, catalogar y analizar sistemáticamente decenas de miles de moléculas alimentarias— representa un avance crucial. Al revelar los mecanismos moleculares a través de los cuales estos compuestos interactúan con las vías biológicas humanas, esta estrategia no solo refina nuestra definición de calidad dietética, sino que también abre nuevas vías para terapias dirigidas y nutrición de precisión. Estamos solo al comienzo de este viaje. Aunque hasta la fecha hemos documentado más de 139.000 moléculas en los alimentos, la gran mayoría de ellas aún desconocemos si se absorben tras la ingestión, cómo se metabolizan (por el microbioma intestinal, el huésped o ambos), a qué proteínas se unen y qué procesos celulares afectan. Descubrir este conocimiento podría revolucionar nuestra perspectiva sobre el papel de los alimentos en la salud. Actualmente carecemos de un plan institucional o de financiación para lograr este objetivo y mapear la composición molecular de los alimentos. Por ejemplo, el primer objetivo del Plan Estratégico 2020-2030 para la Investigación en Nutrición de los NIH 64 de los Institutos Nacionales de la Salud (NIH) se titula «Estimular el descubrimiento y la innovación a través de la investigación fundamental: ¿qué comemos y cómo nos afecta?». Sin embargo, el plan se centra principalmente en la identificación de metabolitos desconocidos que surgen del microbioma y el metabolismo del huésped, sin abordar la necesidad de comprender los compuestos químicos en los alimentos.
En el año fiscal 2019, los NIH gastaron aproximadamente $1.9 mil millones en investigación en nutrición y financiaron aproximadamente 4600 proyectos en al menos 25 de los 27 institutos, centros y oficinas de los NIH. 65 Aunque esta inversión es loable, sin esfuerzos sistemáticos para mapear la NDM, el esfuerzo tendrá un efecto cuestionable, ya que se basa en información muy limitada sobre la composición de los alimentos.
Dado el papel fundamental que desempeña la nutrición en la prevención y el tratamiento de las enfermedades, la falta de inversión concentrada en proyectos fundamentales que mapeen la composición química de los alimentos sigue limitando nuestra capacidad de convertir la ciencia de la nutrición en una disciplina precisa, predictiva y basada en datos.
