Pranav Rajpurkar, Emma Chen Oishi Banerjee y Eric J. Topol
La inteligencia artificial (IA) está a punto de remodelar ampliamente la medicina, lo que podría mejorar las experiencias tanto de los médicos como de los pacientes. Analizamos los hallazgos clave de un esfuerzo semanal de 2 años para rastrear y compartir desarrollos clave en IA médica. Cubrimos estudios prospectivos y avances en el análisis de imágenes médicas, que han reducido la brecha entre la investigación y la implementación. También abordamos varias vías prometedoras para la investigación médica novedosa de la IA, incluidas las fuentes de datos no relacionadas con la imagen, las formulaciones de problemas no convencionales y la colaboración entre humanos e IA. Por último, consideramos los serios desafíos técnicos y éticos en cuestiones que van desde la escasez de datos hasta los prejuicios raciales. A medida que se abordan estos desafíos, se puede aprovechar el potencial de la IA, haciendo que la atención médica sea más precisa, eficiente y accesible para los pacientes de todo el mundo.
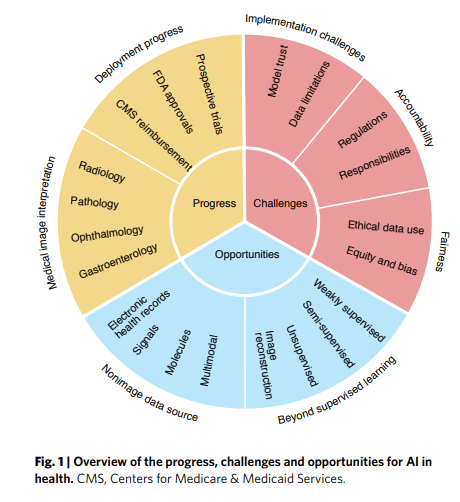
En los próximos años, la IA está preparada para remodelar ampliamente la medicina. Tan solo unos años después de las primeras demostraciones históricas de algoritmos de IA médica que son capaces de detectar enfermedades a partir de imágenes médicas a nivel de expertos1–4 , el panorama de la IA médica ha madurado considerablemente. Hoy en día, el despliegue de sistemas de IA médica en la atención clínica rutinaria presenta una oportunidad importante, pero en gran medida no aprovechada, ya que la comunidad de IA médica navega por los complejos desafíos éticos, técnicos y centrados en el ser humano necesarios para una traducción segura y eficaz. En esta revisión, resumimos los principales avances y destacamos las tendencias generales, proporcionando una visión general concisa del estado de la IA médica. Nuestra revisión se basa en nuestros esfuerzos durante los últimos 2 años, durante los cuales rastreamos y compartimos semanalmente los desarrollos recientes en IA médica (https://doctorpenguin.com). En primer lugar, resumimos los avances recientes, destacando los estudios que han demostrado rigurosamente la utilidad de los sistemas médicos de IA. En segundo lugar, examinamos vías prometedoras para la investigación médica de la IA en forma de nuevas fuentes de datos y analizamos las configuraciones de colaboración entre la IA y los humanos, que tienen más probabilidades de reflejar la práctica médica real que los diseños de estudio típicos que enfrentan a la IA con los humanos. Por último, analizamos los principales retos a los que se enfrenta este campo, como las limitaciones tecnológicas de la IA en su versión actual y las preocupaciones éticas sobre la regulación de los sistemas de IA, la responsabilización de las personas cuando se producen errores de IA, el respeto de la privacidad y el consentimiento del paciente en la recopilación de datos y la protección contra el refuerzo de las inequidades (Fig. 1).
Avances recientes en el despliegue de algoritmos de IA en medicina
Aunque se ha demostrado repetidamente que los sistemas de IA tienen éxito en una amplia variedad de estudios médicos retrospectivos, son relativamente pocas las herramientas de IA que se han trasladado a la práctica médica5 . Los críticos señalan que, en la práctica, los sistemas de IA pueden ser menos útiles de lo que sugieren los datos retrospectivos6 ; los sistemas pueden ser demasiado lentos o complicados para ser útiles en entornos médicos reales7 , o pueden surgir complicaciones imprevistas por la forma en que interactúan los seres humanos y las IA8 . Además, los conjuntos de datos retrospectivos in silico se someten a un extenso filtrado y limpieza, lo que puede hacerlos menos representativos de la práctica médica del mundo real. Los ensayos controlados aleatorios (ECA) y los estudios prospectivos pueden cerrar esta brecha entre la teoría y la práctica, demostrando de manera más rigurosa que los modelos de IA pueden tener un impacto positivo y cuantificable cuando se implementan en entornos de atención médica reales. Recientemente, los ECA han probado la utilidad de los sistemas de IA en la atención sanitaria. Además de la precisión, se han utilizado otras métricas para evaluar la utilidad de la IA, proporcionando una visión holística de su impacto en los sistemas médicos9–13. Por ejemplo, un ECA que evaluó un sistema de IA para administrar dosis de insulina midió la cantidad de tiempo que los pacientes pasaban dentro del rango objetivo de glucosa14; Un estudio que evaluó un sistema de monitoreo de la hipotensión intraoperatoria rastreó la duración promedio de los episodios de hipotensión15, mientras que un sistema que señaló los casos de hemorragia intracraneal para revisión en humanos fue juzgado por su reducción del tiempo de respuesta16. Las directrices recientes, como las extensiones específicas de la IA a las directrices SPIRIT y CONSORT y las próximas directrices, como STARD-AI, pueden ayudar a estandarizar los informes de IA médica, incluidos los protocolos y los resultados de los ensayos clínicos, lo que facilita que la comunidad comparta los hallazgos e investigue rigurosamente la utilidad de la IA médica17,18. En los últimos años, algunas herramientas de IA han pasado de las pruebas a la implementación, ganando apoyo administrativo y eliminando obstáculos regulatorios. El Centro de Servicios de Medicare y Medicaid, que aprueba los costos de reembolso de los seguros públicos, ha facilitado la adopción de la IA en entornos clínicos al permitir el reembolso por el uso de dos sistemas de IA específicos para el diagnóstico de imágenes médicas19. Además, un estudio de 2020 descubrió que la Administración de Alimentos y Medicamentos de EE. UU. (FDA, por sus siglas en inglés) está aprobando productos de IA, en particular de aprendizaje automático (ML; un tipo de IA), a un ritmo acelerado20. Estos avances se traducen en gran medida en autorizaciones de la FDA, que exigen que los productos cumplan con un estándar regulatorio más bajo que las aprobaciones completas, pero no obstante están despejando el camino para que los sistemas de IA/ML se utilicen en entornos clínicos reales. Es importante señalar que los conjuntos de datos utilizados para estas autorizaciones regulatorias a menudo se componen de datos retrospectivos de una sola institución que en su mayoría no se publican y se consideran propietarios. Para generar confianza en los sistemas de IA médica, se requerirán estándares más estrictos para la transparencia y la validación de los informes, incluidas las demostraciones del impacto en los resultados clínicos.
Deep learning para la interpretación de imágenes médicas.
En los últimos años, el aprendizaje profundo, en el que las redes neuronales aprenden patrones directamente de los datos sin procesar, ha logrado un éxito notable en la clasificación de imágenes. En consecuencia, la investigación médica con IA ha florecido en especialidades que dependen en gran medida de la interpretación de imágenes, como la radiología, la patología, la gastroenterología y la oftalmología
Los sistemas de IA han logrado mejoras considerables en la precisión de las tareas de radiología, incluida la interpretación de mamografías21,22, la evaluación de la función cardíaca23,24 y el cribado del cáncer de pulmón25, abordando no solo el diagnóstico, sino también la predicción del riesgo y el tratamiento26. Por ejemplo, se entrenó un sistema de IA para estimar el riesgo de cáncer de pulmón a 3 años a partir de las lecturas de tomografía computarizada (TC) de los radiólogos y otra información clínica27. Estas predicciones podrían usarse para programar tomografías computarizadas de seguimiento para pacientes con cáncer, lo que aumentaría las pautas actuales de detección. La validación de estos sistemas en múltiples centros clínicos y un número cada vez mayor de evaluaciones prospectivas han acercado la IA a su despliegue y a su impacto práctico en el campo de la radiología. En el campo de la patología, la IA ha hecho grandes avances en el diagnóstico de cánceres y ha proporcionado nuevos conocimientos sobre la enfermedad28-33, en gran parte mediante el uso de imágenes de portaobjetos completos. Los modelos han sido capaces de identificar de manera eficiente las áreas de interés dentro de las diapositivas, lo que podría acelerar los flujos de trabajo para el diagnóstico. Más allá de este impacto práctico, las redes neuronales profundas se han entrenado para discernir el origen del tumor primario y detectar variantes estructurales o mutaciones conductoras, lo que proporciona beneficios más allá incluso de las revisiones de patólogos expertos. Además, se ha demostrado que la IA realiza predicciones de supervivencia más precisas para una amplia gama de tipos de cáncer en comparación con la clasificación convencional y la subtipificación histopatológica31. Estos estudios han demostrado cómo la IA puede hacer que las interpretaciones de patologías sean más eficientes, precisas y útiles. El aprendizaje profundo también ha avanzado en gastroenterología, especialmente en términos de mejorar la colonoscopia, un procedimiento clave utilizado para detectar el cáncer colorrectal. El aprendizaje profundo se ha utilizado para predecir automáticamente si las lesiones colónicas son malignas, con un rendimiento comparable al de los endoscopistas expertos34. Además, debido a que los pólipos y otros posibles signos de enfermedad con frecuencia se pasan por alto durante el examen35, se han desarrollado sistemas de IA para ayudar a los endoscopistas. Se ha demostrado que estos sistemas mejoran la capacidad de los endoscopistas para detectar irregularidades, lo que podría mejorar la sensibilidad y hacer de la colonoscopia una herramienta más fiable para el diagnóstico10,11,36. Los modelos de aprendizaje profundo se han aplicado ampliamente en el área de la oftalmología, logrando importantes avances hacia su implementación7,37-41. Además de cuantificar el rendimiento de los modelos, los estudios han investigado el impacto humano de dichos modelos en los sistemas de salud. Por ejemplo, un estudio examinó cómo un sistema de IA para el cribado de enfermedades oculares afectaba a la experiencia del paciente y a los flujos de trabajo médicos, utilizando la observación humana y las entrevistas7 . Otros estudios han analizado el impacto financiero de la IA en el ámbito de la oftalmología, encontrando que el cribado semiautomatizado40 o totalmente automatizado con IA39 podría proporcionar ahorros de costes en contextos específicos, como la detección de la retinopatía diabética.
Oportunidades para el desarrollo de algoritmos de IA
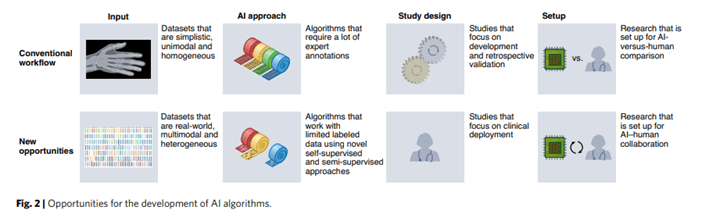
Los estudios médicos de IA a menudo siguen un patrón familiar, abordando un problema de clasificación de imágenes, utilizando el aprendizaje supervisado en datos etiquetados para entrenar un sistema de IA y luego evaluando el sistema comparándolo con expertos humanos. A pesar de que estos estudios han logrado avances notables, presentamos otras tres prometedoras vías de investigación que rompen con este molde (Fig. 2). En primer lugar, abordamos las fuentes de datos que no son imágenes, como las secuencias de texto, químicas y genómicas, que pueden proporcionar información médica valiosa. En segundo lugar, discutimos las formulaciones de problemas que van más allá del aprendizaje supervisado, obteniendo información a partir de datos no etiquetados o imperfectos a través de paradigmas como el aprendizaje no supervisado o semisupervisado. Por último, nos fijamos en los sistemas de IA que colaboran con los humanos en lugar de competir contra ellos, lo que supone un camino para lograr un mejor rendimiento que la IA o los humanos solos.
Datos médicos más allá de las imágenes.
Más allá de la clasificación de imágenes, los modelos de aprendizaje profundo pueden aprender de muchos tipos de datos de entrada, incluidos números, texto o incluso combinaciones de tipos de entrada. El trabajo reciente se ha basado en una variedad de fuentes de datos ricas que involucran información molecular, lenguaje natural, señales médicas como datos de electroencefalograma (EEG) y datos multimodales. A continuación se muestra un resumen de las aplicaciones que utilizan estas fuentes de datos. La IA ha permitido avances recientes en el área de la bioquímica, mejorando la comprensión de la estructura y el comportamiento de las biomoléculas42-45. El trabajo de Senior et al. sobre AlphaFold representó un gran avance en la tarea clave del plegamiento de proteínas, que consiste en predecir la estructura 3D de una proteína a partir de su secuencia química42. Las mejoras en la predicción de la estructura de las proteínas pueden proporcionar información mecanicista sobre una serie de fenómenos, como las interacciones entre fármacos y proteínas o los efectos de las mutaciones. Alley et al. también avanzaron en el área del análisis de proteínas, creando resúmenes estadísticos que capturan las propiedades clave de las proteínas y ayudan a las redes neuronales a aprender con menos datos43. Al utilizar estos resúmenes en lugar de secuencias químicas en bruto, los modelos para tareas posteriores, como la predicción de la función molecular, pueden obtener un alto rendimiento con muchos menos datos etiquetados. La IA también ha hecho avances en el campo de la genómica, a pesar de la complejidad del modelado de las interacciones genómicas en 3D. Cuando se aplica a los datos sobre el ADN libre de células circulantes, la IA ha permitido la detección no invasiva del cáncer, el pronóstico y la identificación del origen del tumor46-48. El aprendizaje profundo ha mejorado los esfuerzos de edición de genes basados en CRISPR, ayudando a predecir la actividad del ARN guía e identificar familias de proteínas anti-CRISPR49,50. Además, se ha utilizado el análisis basado en IA de datos transcriptómicos y genómicos microbianos para detectar rápidamente la resistencia a los antibióticos en los patógenos. Este avance permite a los médicos seleccionar rápidamente los tratamientos más efectivos, lo que podría reducir la mortalidad y evitar el uso innecesario de antibióticos de amplio espectro51. Además, la IA está empezando a acelerar el proceso de descubrimiento de fármacos. Se ha demostrado que los modelos de aprendizaje profundo para el análisis molecular aceleran el descubrimiento de nuevos fármacos al reducir la necesidad de experimentos físicos más lentos y costosos. Estos modelos han demostrado ser útiles para predecir propiedades físicas relevantes, como la bioactividad o la toxicidad de posibles fármacos. Un estudio utilizó la IA para:
identificar un fármaco que posteriormente demostró ser eficaz para combatir las bacterias resistentes a los antibióticos en modelos experimentales52. Otro fármaco diseñado por IA demostró inhibir DDR1 (un receptor implicado en varias enfermedades, incluida la fibrosis) en modelos experimentales; Sorprendentemente, se descubrió en solo 21 días y se probó experimentalmente en 46 días, acelerando drásticamente un proceso que generalmente lleva varios años53. Es importante destacar que los modelos de aprendizaje profundo pueden seleccionar moléculas efectivas que difieren de los medicamentos existentes de manera clínicamente significativa, abriendo así nuevas vías para el tratamiento y proporcionando nuevas herramientas en la lucha contra los patógenos resistentes a los medicamentos. Investigaciones recientes han explotado la disponibilidad de grandes conjuntos de datos de textos médicos para tareas de procesamiento del lenguaje natural relacionadas con la atención médica, aprovechando avances técnicos como transformadores e incrustaciones de palabras contextuales (dos tecnologías que ayudan a los modelos a considerar el contexto circundante al interpretar cada parte de un texto). Un estudio presentó BioBERT, un modelo entrenado en un gran corpus de textos médicos que superaba el rendimiento previo del estado del arte en tareas de lenguaje natural, como responder a preguntas biomédicas54. Estos modelos se han utilizado para mejorar el rendimiento en tareas como aprender de la literatura biomédica qué fármacos se sabe que interactúan entre sí55 o etiquetar automáticamente los informes radiológicos56. También se han extraído grandes conjuntos de datos de texto de las redes sociales y se han utilizado para rastrear las tendencias de salud mental a gran escala57. Por lo tanto, los avances en el procesamiento del lenguaje natural han abierto una gran cantidad de nuevos conjuntos de datos y oportunidades de IA, aunque todavía existen limitaciones importantes debido a la dificultad de extraer información de secuencias de texto largas. Además, se han utilizado métodos de ML para predecir resultados a partir de datos de señales médicas, como EEG58, electrocardiograma59,60 y datos de audio61. Por ejemplo, el ML aplicado a las señales de EEG de pacientes clínicamente no respondientes con lesiones cerebrales permitió la detección de la actividad cerebral, un predictor de una eventual recuperación58. Además, la capacidad de la IA para transformar directamente las ondas cerebrales en habla o texto tiene un notable valor potencial para los pacientes con afasia o síndrome de enclaustramiento que han sufrido accidentes cerebrovasculares62. Los datos de señales médicas también se pueden recopilar de forma pasiva fuera de un entorno clínico en el mundo real mediante el uso de sensores portátiles, como los relojes inteligentes, que permiten la monitorización remota de la salud59,63. Algunos modelos de aprendizaje profundo integran múltiples fuentes de datos médicos para un enfoque multimodal64-68. Por ejemplo, un modelo para el diagnóstico de trastornos respiratorios tomó como entrada grabaciones de audio de la tos de los pacientes, así como informes de sus síntomas65. Los modelos multimodales también han aprovechado insumos mucho más complejos, como las historias clínicas electrónicas, que abarcan una amplia variedad de datos como diagnósticos médicos, signos vitales, recetas y resultados de laboratorio66,67. Dichos modelos pueden hacer predicciones basadas en diversos tipos de datos, al igual que los médicos humanos se basan en múltiples tipos de información al tomar decisiones en la práctica. A pesar de su potencial, esta área de investigación parece relativamente poco desarrollada, en parte debido a los desafíos de recopilar múltiples tipos de datos de manera consistente en todos los departamentos o instituciones. No obstante, esperamos que el uso de modelos multimodales aumente con el tiempo.
Configuraciones de IA más allá del aprendizaje supervisado.
Además de utilizar nuevas fuentes de datos, estudios recientes han probado formulaciones de problemas no convencionales. Convencionalmente, los conjuntos de datos derivan entradas y etiquetas de datos reales, y modelos como las redes neuronales se utilizan para aprender el mapeo de funciones de las entradas a las etiquetas. Sin embargo, debido a que el etiquetado puede ser costoso y llevar mucho tiempo, los conjuntos de datos que contienen entradas y etiquetas precisas suelen ser difíciles de obtener y se reutilizan con frecuencia en muchos estudios. Otros paradigmas, como el aprendizaje no supervisado (específicamente el aprendizaje autosupervisado), el aprendizaje semisupervisado, la inferencia causal y el aprendizaje por refuerzo (Recuadro 1), se han utilizado para abordar problemas en los que los datos no están etiquetados o son ruidosos. Estos avances han ampliado los límites de la IA médica, mejorando las tecnologías existentes y profundizando la comprensión de las enfermedades. El aprendizaje no supervisado, que implica aprender de datos sin etiquetas, ha proporcionado información procesable, lo que permite a los modelos encontrar patrones y categorías novedosas en lugar de limitarse a las etiquetas existentes, como en el paradigma supervisado69-73,74. Por ejemplo, los algoritmos de agrupamiento, que organizan puntos de datos no etiquetados agrupando puntos de datos similares, se han aplicado a afecciones como la sepsis, el cáncer de mama y la endometriosis, identificando subgrupos de pacientes clínicamente significativos29,74,75,76. Estas categorías pueden revelar nuevos patrones en la manifestación de la enfermedad que, con el tiempo, pueden ayudar a determinar el diagnóstico, el pronóstico y el tratamiento. Otras formulaciones se basan en la extracción de información a partir de datos ruidosos o imperfectos, lo que reduce drásticamente el costo de la recopilación de datos30,77. A modo de ejemplo, Campanella et al. entrenaron un modelo débilmente supervisado para diagnosticar varios tipos de cáncer a partir de imágenes de portaobjetos completos, utilizando solo los diagnósticos finales como etiquetas y omitiendo la anotación de píxeles que se espera en una configuración de aprendizaje supervisado. Con este enfoque, lograron excelentes resultados de clasificación, incluso con costos de anotación reducidos30. También se han utilizado formulaciones de problemas no convencionales para mejorar y reconstruir imágenes78-81. Por ejemplo, al crear un modelo para mejorar el detalle espacial en imágenes de resonancia magnética (IRM) de baja calidad, Masutani et al. generaron sintéticamente datos de entrada; tomaron imágenes de resonancia magnética de alta calidad, agregaron ruido al azar y luego entrenaron una red neuronal convolucional (un tipo de red neuronal comúnmente utilizada para datos de imágenes) para recuperar las imágenes de resonancia magnética originales de alta calidad de sus entradas simuladas de «baja calidad»80. Estas formulaciones permiten a los investigadores aprovechar grandes conjuntos de datos, a pesar de sus imperfecciones, para entrenar modelos de alto rendimiento.
Configuraciones más allá de lo humano frente a la IA.
Aunque la mayoría de los estudios se han centrado en una comparación directa de la IA con los humanos82, es más probable que la práctica médica de la vida real implique configuraciones humanas en el circuito, donde los humanos colaboran activamente con los sistemas de IA y Proporcionar supervisión83,84.
Por lo tanto, estudios recientes han comenzado a explorar tales configuraciones colaborativas entre la IA y los humanos. Estas configuraciones suelen contar con humanos que reciben asistencia de la IA, aunque ocasionalmente la IA y los humanos trabajan por separado y sus predicciones se promedian o combinan posteriormente. Múltiples estudios sobre una variedad de tareas han demostrado que los expertos clínicos y la IA en combinación logran un mejor rendimiento que los expertos solos21,85-89. Por ejemplo, Sim et al. descubrieron que los expertos clínicos asistidos por IA superaron tanto a los humanos como a la IA sola al detectar nódulos malignos en las radiografías de tórax85. Es probable que la utilidad de la colaboración entre humanos e IA dependa de las características específicas de la tarea y del contexto clínico. Todavía hay preguntas abiertas sobre cómo exactamente la asistencia de la IA afecta el rendimiento humano. Por ejemplo, a veces se ha demostrado que la asistencia de la IA mejora la sensibilidad de los expertos clínicos al tiempo que reduce su especificidad8,86, y algunos estudios, tanto prospectivos como retrospectivos, han encontrado que el rendimiento combinado de la IA y el ser humano no podría superar el rendimiento de la IA por sí sola90,91. Además, algunos médicos pueden beneficiarse más de la asistencia de la IA que otros; los estudios sugieren que los médicos menos experimentados, como los aprendices, se benefician más de los aportes de la IA que sus pares más experimentados8,92. Las consideraciones técnicas también desempeñan un papel importante a la hora de determinar la eficacia de la asistencia de la IA. Como era de esperar, la precisión de los consejos de la IA puede afectar a su utilidad, por lo que se ha descubierto que las predicciones incorrectas dificultan el rendimiento de los clínicos, incluso si las predicciones correctas resultan útiles8 . Además, las predicciones de IA se pueden comunicar de múltiples maneras, apareciendo, por ejemplo, como probabilidades, recomendaciones de texto o imágenes editadas para resaltar áreas de interés. Se ha demostrado que el formato de presentación de la asistencia de IA afecta a su utilidad para los usuarios humanos90,91, por lo que el trabajo futuro en la optimización de la asistencia médica de IA puede basarse en las investigaciones existentes sobre las interacciones humano-ordenador.
Desafíos para el futuro del campo
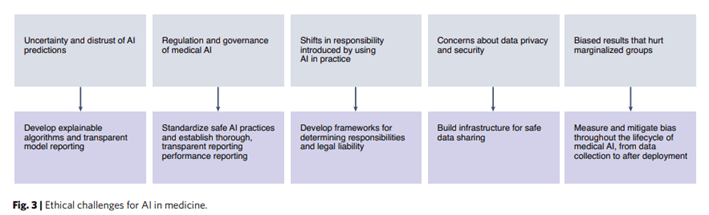
A pesar de los sorprendentes avances, el campo de la IA médica se enfrenta a importantes desafíos técnicos, especialmente en términos de generar confianza en los usuarios en los sistemas de IA y componer conjuntos de datos de entrenamiento. También quedan preguntas sobre la regulación de la IA en la medicina y las formas en que la IA puede cambiar y crear responsabilidades en todo el sistema sanitario, afectando tanto a los investigadores como a los médicos y a los pacientes. Por último, existen importantes preocupaciones éticas sobre el uso de los datos y la equidad en la IA médica (Fig. 3).
Desafíos de implementación.
Limitaciones del conjunto de datos. Los datos de IA médica a menudo plantean desafíos específicos y prácticos. Aunque se espera que la IA reduzca los costos médicos, los dispositivos necesarios para obtener los insumos para los sistemas de IA pueden ser prohibitivos. En concreto, el equipo necesario para capturar imágenes de portaobjetos completos es costoso y, por lo tanto, no está disponible en muchos sistemas de salud, lo que impide tanto la recopilación de datos como el despliegue de sistemas de IA para patología. Los tamaños de imagen grandes plantean preocupaciones adicionales, ya que la cantidad de memoria requerida por una red neuronal puede aumentar tanto con la complejidad del modelo como con el número de píxeles en la entrada. Como resultado, muchas imágenes médicas, especialmente las imágenes de diapositivas completas, que pueden contener fácilmente miles de millones de píxeles cada una, son demasiado grandes para caber en la red neuronal promedio. Existen muchas maneras de abordar este problema. Las imágenes pueden cambiar de tamaño a expensas de los detalles finos, o pueden dividirse en varios parches pequeños, aunque esto dificultará la capacidad del sistema para establecer conexiones entre diferentes áreas de la imagen. En otros casos, los humanos pueden identificar una región de interés más pequeña, como parte de una imagen de portaobjetos que contiene un tumor, y recortar la imagen antes de introducirla en un sistema de IA, aunque esta intervención añade un paso manual a lo que de otro modo podría ser un flujo de trabajo totalmente automatizado32,93. Algunos estudios utilizan modelos personalizados de gran tamaño que pueden aceptar imágenes médicas completas, pero la ejecución de estos modelos puede requerir hardware costoso con más memoria. Por lo tanto, los sistemas para la clasificación de imágenes médicas a menudo implican compensaciones para hacer que las entradas sean compatibles con las redes neuronales. Otro problema que afecta a las imágenes, así como a muchos otros tipos de datos médicos, es la escasez de las etiquetas necesarias para el aprendizaje supervisado94. Las etiquetas suelen ser asignadas a mano por expertos médicos, pero este enfoque puede resultar difícil debido al tamaño del conjunto de datos, las limitaciones de tiempo o la escasez de experiencia. En otros casos, las etiquetas pueden ser proporcionadas por humanos no expertos, por ejemplo, a través de crowdsourcing. Sin embargo, estas etiquetas pueden ser menos precisas, y los proyectos de etiquetado colaborativo se enfrentan a complicaciones asociadas con la privacidad, ya que los datos deben compartirse con muchos etiquetadores. Las etiquetas también pueden ser aplicadas por otros modelos de IA, como en algunas configuraciones de supervisión débil95, pero estas etiquetas también conllevan el riesgo de ruido. En la actualidad, la dificultad de obtener etiquetas de calidad es un obstáculo importante para los proyectos de aprendizaje supervisado, lo que genera interés en plataformas que hacen más eficiente el etiquetado y en configuraciones débilmente supervisadas y no supervisadas que requieren menos esfuerzo de etiquetado. Los problemas también surgen cuando los factores tecnológicos conducen a sesgos en los conjuntos de datos. Por ejemplo, el sesgo de una sola fuente se produce cuando un único sistema genera un conjunto de datos completo, como cuando todas las imágenes de una colección proceden de una sola cámara con ajustes fijos. Los modelos que muestran un sesgo de una sola fuente pueden tener un rendimiento inferior en las entradas recopiladas de otras fuentes. Para mejorar la generalización, los modelos pueden someterse a un entrenamiento específico del sitio para adaptarse a las peculiaridades específicas de cada lugar donde se despliegan, y también pueden ser entrenados y validados en conjuntos de datos recopilados de diferentes fuentes94,96. Sin embargo, este último enfoque debe llevarse a cabo con cuidado, especialmente cuando la distribución de las etiquetas difiere drásticamente entre los conjuntos de datos. Por ejemplo, si un modelo se entrena con conjuntos de datos de dos instituciones, una que contiene solo casos positivos y otra que contiene solo casos negativos, entonces puede lograr un alto rendimiento a través de «atajos» espurios sin aprender sobre la patología relevante. Por lo tanto, un modelo de clasificación de imágenes podría basar sus predicciones completamente en las diferencias entre las cámaras de las dos instituciones; Es probable que un modelo de este tipo no aprenda nada sobre la enfermedad subyacente y no logre generalizar

en otra parte. Por lo tanto, alentamos a los investigadores a desconfiar de los sesgos tecnológicos, incluso cuando utilicen datos de diversas fuentes97.
Construyendo modelo de confianza.
Se desea una variedad de cualidades para que un sistema de IA se gane la confianza del usuario. Por ejemplo, es útil que los sistemas de IA sean fiables, cómodos de usar y fáciles de integrar en los flujos de trabajo clínicos98. Los sistemas de IA pueden empaquetarse con instrucciones fáciles de leer, que explican cómo y cuándo deben utilizarse; Puede ser útil que estos manuales de usuario se estandaricen en todos los sistemas99. La explicabilidad es otro aspecto clave para ganarse la confianza, ya que es más fácil creer en las predicciones de un sistema de IA cuando el sistema puede explicar cómo llegó a sus conclusiones. Debido a que muchos sistemas de IA funcionan actualmente como «cajas negras» ininterpretables, explicar sus predicciones plantea un serio desafío técnico. Existen algunos métodos para explicar las predicciones de la IA, como los métodos de prominencia que resaltan las regiones de una imagen que más contribuyen a la predicción de una enfermedad por parte de un modelo. Sin embargo, es posible que estos métodos no sean fiables100, y se necesita más investigación para interpretar los procesos de toma de decisiones de la IA, cuantificar su fiabilidad y transmitir esas interpretaciones con claridad al público humano101. Además de generar confianza entre los usuarios, la mejora de la explicabilidad permitirá a los desarrolladores comprobar los modelos más a fondo en busca de errores y verificar hasta qué punto la toma de decisiones de la IA refleja los enfoques humanos expertos102. Además, cuando los modelos médicos de IA logran nuevos conocimientos que van más allá del conocimiento humano actual, una mejor explicabilidad puede ayudar a los investigadores a comprender esos nuevos conocimientos y, por lo tanto, a comprender mejor los mecanismos biológicos detrás de la enfermedad. Quizás el componente más obvio de la confiabilidad es la precisión, porque es poco probable que los usuarios confíen en un modelo que no se ha demostrado rigurosamente que da predicciones correctas. Además, los estudios de IA fiables deben ser reproducibles, de modo que el entrenamiento repetido de un modelo con un conjunto de datos y un protocolo determinados produzca resultados coherentes. Los estudios también deben ser replicables, de modo que los modelos funcionen de manera consistente incluso cuando se entrenan con diferentes muestras de datos. Desafortunadamente, demostrar la reproducibilidad y replicabilidad de los estudios de IA plantea desafíos únicos. Los conjuntos de datos, el código y los modelos entrenados a menudo no se publican, lo que dificulta que la comunidad de IA en general verifique y se base en los resultados anteriores de forma independiente103,104.
Responsabilidad.
Desafíos regulatorios. Trabajos recientes ponen de relieve los problemas regulatorios relacionados con el despliegue de modelos de IA para la atención sanitaria. Más allá de la precisión, los reguladores pueden analizar una variedad de criterios para evaluar los modelos. Por ejemplo, pueden requerir estudios de validación que demuestren que los sistemas de IA son robustos y generalizables en entornos clínicos y poblaciones de pacientes y garantizan que los sistemas protejan la privacidad del paciente. Además, dado que la utilidad de los sistemas de IA puede depender en gran medida de la forma en que los humanos proporcionan información e interpretan la salida, los reguladores pueden requerir pruebas de factores humanos y una capacitación adecuada para los usuarios humanos de los sistemas médicos de IA105. Los desafíos regulatorios específicos surgen del aprendizaje continuo, donde los modelos aprenden de nuevos datos a lo largo del tiempo y se ajustan a los cambios en las poblaciones de pacientes, ya que esto puede conllevar el riesgo de sobrescribir patrones previamente aprendidos o causar nuevos errores106. Tradicionalmente, los reguladores de los sistemas de IA aprueban solo un conjunto bloqueado de parámetros, pero este enfoque no tiene en cuenta la necesidad de actualizar los modelos, a medida que los datos evolucionan debido a los cambios en las poblaciones de pacientes, las herramientas de recopilación de datos y la gestión de la atención. Por lo tanto, los reguladores deben desarrollar nuevos procesos de certificación para manejar dichos sistemas. Es importante destacar que la FDA ha propuesto recientemente un marco para los sistemas de IA adaptativa en el que aprobarían no solo un modelo inicial, sino también un proceso para actualizarlo con el tiempo107.
Cambios en la responsabilidad.
Aunque los sistemas de IA tienen el potencial de empoderar a los humanos en la toma de decisiones médicas, también corren el riesgo de limitar la autonomía personal y crear nuevas obligaciones. A medida que los sistemas de IA asumen más responsabilidades en el entorno sanitario, una preocupación a la que se enfrenta el sistema es que los médicos puedan volverse demasiado dependientes de la IA, tal vez viendo una disminución gradual de sus propias habilidades o conexiones personales con los pacientes. A su vez, los desarrolladores de IA médica pueden tener una gran influencia en la atención sanitaria y, por lo tanto, deben estar obligados a crear sistemas de IA seguros y útiles e influir de manera responsable en las opiniones públicas sobre la salud. A medida que la toma de decisiones médicas se vuelve más dependiente de juicios de IA potencialmente inexplicados, los pacientes individuales pueden perder cierta comprensión o control sobre su propia atención. Al mismo tiempo, los pacientes podrían adquirir nuevas responsabilidades a medida que la IA hace que la atención médica sea más omnipresente en la vida diaria. Por ejemplo, si los dispositivos inteligentes proporcionan a los pacientes consejos constantes, se puede esperar que esos pacientes sigan esas recomendaciones o, de lo contrario, sean responsables de resultados negativos para la salud108. La proliferación de la IA también plantea preocupaciones en torno a la rendición de cuentas, ya que actualmente no está claro si los desarrolladores, reguladores, vendedores o proveedores de atención médica deben rendir cuentas si un modelo comete errores incluso después de haber sido validado clínicamente a fondo. Actualmente, los médicos son responsables cuando se desvían del estándar de atención y ocurren lesiones en el paciente. Si los médicos son generalmente escépticos con respecto a la IA médica, entonces los médicos individuales pueden verse influenciados negativamente para ignorar las recomendaciones de la IA que entran en conflicto con la práctica estándar, incluso si esas recomendaciones pueden ser personalizadas y beneficiosas para un paciente específico. Sin embargo, si el estándar de atención cambia para que los médicos utilicen de forma rutinaria las herramientas de IA, entonces habrá un fuerte incentivo médico-legal para que los médicos sigan las recomendaciones de IA109.
Equidad. Uso ético de los datos. Existe la preocupación de que los malos actores interesados en el robo de identidad y otras conductas indebidas puedan aprovecharse de los conjuntos de datos médicos, que a menudo contienen grandes cantidades de información confidencial sobre pacientes reales. La descentralización del almacenamiento de datos es una forma de reducir el daño potencial de cualquier hackeo o fuga de datos individual. El proceso de aprendizaje federado facilita dicha descentralización al tiempo que facilita la colaboración entre instituciones sin complicados acuerdos de intercambio de datos (Fig. 4). Cuando se utiliza el aprendizaje federado, los desarrolladores envían modelos de IA a diferentes instituciones que tienen conjuntos de datos privados; Las instituciones entrenan los modelos con sus datos y envían actualizaciones de los modelos sin compartir nunca los datos110. Sin embargo, incluso después de entrenar los modelos, sigue existiendo el riesgo de que los sistemas de IA se enfrenten a ataques a la privacidad, que a veces pueden reconstruir los puntos de datos originales utilizados en el entrenamiento con solo examinar el modelo resultante. Los datos de los pacientes pueden protegerse mejor de este tipo de ataques si las entradas se cifran antes del entrenamiento, pero este enfoque se produce a costa de la interpretabilidad del modelo111. Más allá de estos ataques de mala fe, hay otras preguntas sobre cómo respetar la privacidad de los pacientes. Por lo general, los datos confidenciales deben recopilarse y utilizarse en la investigación con el consentimiento del paciente y, cuando sea práctico, se deben utilizar estrategias de anonimización y agregación para ocultar los datos personales. Es necesario garantizar que todas las instituciones que trabajen con datos de pacientes los manejen de manera responsable, ya que

por ejemplo, mediante el uso de protocolos de seguridad adecuados. Al mismo tiempo, también es importante que los datos de los pacientes se utilicen por su bien. Por respeto a los pacientes que han accedido a compartir su información personal, lo ideal sería que los datos de los pacientes se utilizaran para investigaciones que promuevan el bienestar futuro de los pacientes. Desafortunadamente, estos objetivos a veces pueden entrar en conflicto entre sí; La implementación de medidas de seguridad como el aprendizaje federado puede requerir recursos y esfuerzos considerables, y las instituciones que no pueden realizar esas inversiones pueden no poder acceder a ciertos conjuntos de datos, incluso cuando su investigación beneficiaría a los pacientes en cuestión. Además, la reutilización de datos en varios proyectos puede dificultar la obtención del consentimiento informado, ya que los pacientes atraídos por un estudio pueden dudar en unirse a otros. Esperamos y esperamos que la comunidad de IA continúe explorando estas compensaciones y encuentre nuevas formas de equilibrar una variedad de intereses de los pacientes110. Equidad y sesgo. La IA puede hacer que la atención sanitaria sea más accesible para los grupos desatendidos, pero también corre el riesgo de reforzar las desigualdades existentes, ya que los modelos de IA pueden perpetuar los sesgos que acechan en los datos112. Los sistemas de IA médica pueden fallar a la hora de generalizar a nuevos tipos de datos con los que no fueron entrenados; Por lo tanto, es bien sabido que el entrenamiento con conjuntos de datos que subrepresentan a los grupos marginados da lugar a sistemas sesgados que tienen un rendimiento inferior en esos grupos. Los sistemas que tienen en cuenta explícitamente la raza en sus predicciones también corren el riesgo de perpetuar los prejuicios, porque las categorías raciales son difíciles de definir y oscurecen la diversidad dentro de los grupos raciales113. El sesgo puede aparecer debido a otras opciones de diseño, como la elección de la etiqueta de destino. Por ejemplo, se descubrió que un algoritmo de evaluación de riesgos utilizado para guiar la toma de decisiones clínicas de 200 millones de pacientes ofrecía predicciones con sesgos raciales, de modo que los pacientes blancos a los que se les asignaba una determinada puntuación de riesgo predicho tendían a ser más saludables que los pacientes negros con la misma puntuación. Este sesgo se debió en gran parte a las etiquetas originales utilizadas en la capacitación. El sistema fue entrenado para predecir los costos futuros de la atención médica, pero debido a que los pacientes negros habían recibido históricamente una atención menos costosa que los pacientes blancos debido a los sesgos sistemáticos existentes, el sistema reprodujo esos sesgos raciales en sus predicciones114. Se necesita una investigación exhaustiva para detectar y corregir el sesgo en los modelos médicos de IA, ya que el sesgo puede causar un daño generalizado a los grupos marginados si no se controla. En el futuro, las herramientas de IA pueden someterse sistemáticamente a pruebas especiales antes de su implementación para verificar que las redes neuronales sirven al bienestar de las poblaciones marginadas de manera equitativa. Además, puede ser más fácil identificar sesgos peligrosos si mejora la explicabilidad del modelo, porque los monitores humanos podrán verificar el razonamiento de los sistemas de IA e identificar elementos problemáticos115.
Conclusión
El campo de la IA médica ha avanzado considerablemente hacia su implementación a gran escala, especialmente a través de estudios prospectivos como los ECA y mediante el análisis de imágenes médicas, sin embargo, la IA médica aún se encuentra en una fase temprana de validación e implementación. Hasta la fecha, un número limitado de estudios han utilizado la validación externa, la evaluación prospectiva y diversas métricas para explorar el impacto total de la IA en entornos clínicos reales, y la gama de casos de uso evaluados ha sido relativamente limitada. Aunque el campo requiere más pruebas y soluciones prácticas, también se necesita una imaginación audaz. La IA ha demostrado ser capaz de extraer información de fuentes inesperadas y establecer conexiones que los humanos normalmente no anticiparían, por lo que esperamos ver enfoques aún más creativos y fuera de lo común para la IA médica. Existen grandes oportunidades para la investigación novedosa de la IA que involucra tipos de datos que no son imágenes y formulaciones de problemas no convencionales, que abren una gama más amplia de posibles conjuntos de datos. También existen oportunidades en la colaboración entre IA y humanos, una alternativa a las competiciones entre IA y humanos comunes en la investigación; nos gustaría que se estudiaran más las configuraciones colaborativas, ya que pueden proporcionar mejores resultados que la IA o los humanos solos y es más probable que reflejen la práctica médica real. A pesar del potencial de este campo, aún quedan importantes cuestiones técnicas y éticas para la IA médica. A medida que se aborden sistemáticamente estas cuestiones fundamentales, es posible que se materialice el potencial de la IA para mejorar notablemente el futuro de la medicina.
