Medicina Digital volume 7, 381 (2024)
Nota del Blog: El triage para el ordenamiento de las prioridades de ingreso a los sistemas de salud, de acuerdo a la gravedad, hace varias décadas se viene aplicando, el agregado a este sistema reglado y probado de Machine Learning permite hacer más eficiente el sistema y muestra una aplicación de inteligencia artificial que promete mejora, eficiencia y equidad en la organización de la atención. Por ello, se incluye en este capítulo creado el año 2024 de estudio y actualización de la AI que cambiará los esquemas, los flujos de pacientes, el seguimiento y la coparticipación. Para bien, faltará ver algunos otros aspectos ya que esto es un servicio que tiene su costo de inversión, por lo tanto es para sistemas que estén integrados, porque no habría forma de remunerarlos. Hace un tiempo, nuestro sistema de atención desarrollo un bot que da prioridad a algunos pacientes en los lugares donde pueden ser con mayor celeridad.
Resumen:
Los sistemas de acceso inteligente y autotriage para pacientes en servicios de emergencia han estado en desarrollo durante décadas. Hasta el momento, los sistemas de salud no han publicado ningún LLM para el procesamiento de datos de pacientes auto informados. Muchos sistemas expertos y modelos computacionales se han lanzado a millones de personas y países. Esta revisión es la primera en resumir el progreso en el campo, incluyendo un análisis de las soluciones exactas de autotriage disponibles en los sitios web de 647 sistemas de salud en los Estados Unidos.
Introducción
Hoy en día, los pacientes se benefician de los sistemas de autotriage digital, admisión automatizada, diagnóstico diferencial y caracterización de enfermedades1,2,3,4,5,6,7,8,9,10,11,12. Antes de estos sistemas automatizados, los pacientes han tenido que navegar por la toma de decisiones sanitarias apoyada en los límites de su propio conocimiento, los navegadores de búsqueda en Internet y de las personas con las que contactan, en particular los profesionales médicos. Los centros de llamadas de enfermería han existido durante décadas (Fig. 1). Estos servicios permitieron a los pacientes llamar a un número, informar sobre sus síntomas/afecciones y recibir información para respaldar sus decisiones de atención médica (es decir, Apoyo para la Decisión del Paciente (PDS)). Los protocolos de triage telefónico más ampliamente adoptados son los protocolos de triage telefónico (STP) de Schmitt-Thompson, que hoy en día alimentan el 95% de los centros de llamadas de enfermería en todo el país y se utilizan en >200 millones de encuentros13,14,15.
Los STP son un conjunto de reglas de triage que ayudan a determinar si se necesita atención y, de ser así, específicamente qué tipo de atención. Resuelven entre los servicios médicos de emergencia (911), las salas de emergencia, los centros de atención de urgencia y los PCP. ¿Cuántos de nosotros hemos dudado de qué cuidado buscar o si buscarlo en absoluto cuando estamos enfermos?
El propósito de estos STP es estandarizar y mejorar la precisión de la orientación que los profesionales médicos dan por teléfono en un libro de texto publicado por la Academia Americana de Pediatría que se sigue manteniendo14,15. A medida que las líneas de enfermería se convirtieron en una oferta omnipresente en todas las aseguradoras y sistemas de salud, el PDS se convirtió en sólido16,17. A medida que mejoraron las capacidades tecnológicas, la automatización de estas reglas se convirtió en una opción y un medio más sencillo para que los pacientes se autoapoyaran18,19.
Fig. 1: Cronología para el desarrollo de sistemas de inteligencia artificial que utilizan datos autoinformados por los pacientes.
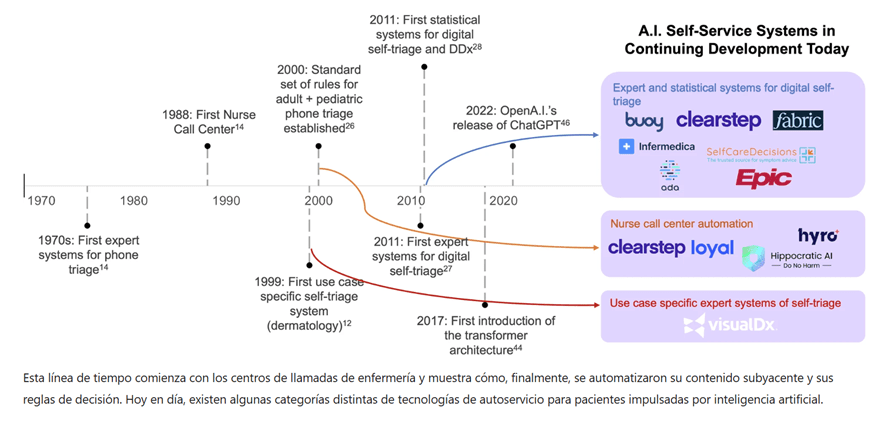
Esta línea de tiempo comienza con los centros de llamadas de enfermería y muestra cómo, finalmente, se automatizaron su contenido subyacente y sus reglas de decisión. Hoy en día, existen algunas categorías distintas de tecnologías de autoservicio para pacientes impulsadas por inteligencia artificial.
Estos sistemas de «triage virtual», que inicialmente ayudaban con la admisión y el triage, estuvieron entre los primeros mecanismos para que los pacientes informaran por sí mismos sus síntomas y recibieran PDS. Sin embargo, la automatización tuvo una contrapartida. El aumento de la velocidad, el anonimato y la comodidad se produjo a costa de una menor capacidad para aclarar e interpretar las respuestas a través de un profesional médico por teléfono 4,9,10,19,20. Por otro lado, el sistema de salud también podría ahorrar dinero optimizando mejor el uso de sus centros de llamadas10.
A medida que la disponibilidad de datos y la capacidad tecnológica mejoraron, también lo hicieron los métodos estadísticos computacionales. Las computadoras fueron programadas para realizar tareas típicamente reservadas a la inteligencia humana (Inteligencia Artificial, IA)21. Eventualmente, se crearon métodos que permitieron a las computadoras aprender de grandes cantidades de datos y generalizar dichos aprendizajes para completar tareas (Machine Learning—ML)22. Si se combina esto con la capacidad de las computadoras para procesar la entrada de lenguaje natural por parte de los usuarios (Procesamiento del Lenguaje Natural, PLN), se establecieron los componentes básicos para motores de diagnóstico diferencial más potentes y capacidades de caracterización de enfermedades 23,24. Finalmente, se desarrollaron el transformador y los grandes modelos de lenguaje (LLM), lo que llevó a otro punto de inflexión 25,26,27. El procesamiento y la generación del lenguaje natural alcanzaron nuevas alturas con la «IA generativa» y la automatización ya no requería una compensación en la capacidad de aclarar o interpretar el lenguaje ingresado por el paciente. Sin embargo, aún existen brechas relacionadas con la alucinación, la interpretabilidad, la validación y la precisión21,29.
La ingesta automatizada, el triage virtual y la predicción diagnóstica diferencial florecieron en la industria y en el mundo de las empresas emergentes 30,31,32,33,34 gracias al hecho de que la FDA ha pasado por múltiples períodos de revisión de borradores de directrices, pero aún no tiene una guía obligatoria sobre los sistemas PDS 35,36. Este artículo de perspectivas profundizará en los matices de los sistemas de triage virtual y diagnóstico diferencial auto informados. Se discutirán varios enfoques para construir, validar y mejorar ambos. Se detallarán las ventajas y desventajas de los sistemas basados en reglas frente a los basados en ML (Tabla 1). Por último, se analizará el panorama regulatorio y las direcciones futuras.
Tabla 1 Ventajas y desventajas de los sistemas expertos y los métodos de aprendizaje estadístico para el autotriaje por parte de los sistemas de salud
| Sistemas basados en expertos | Aprendizaje automático estadístico | ||||
| Ventajas | Desventajas | Ventajas | Desventajas | ||
| Consideraciones importantes sobre las soluciones de autotriage para los sistemas de salud | Validación | Los STP han sido probados en >200 millones de encuentros de enfermería durante 20+ años12,83. | Requiere que un panel de médicos repita la determinación de las reglas exactas. No existe un estándar de oro para el auto-triaje. Lo más parecido es el triaje telefónico84. | Los sistemas de clasificación estadística utilizan grandes conjuntos de datos para entrenar modelos (a menudo una red neuronal) para calcular un nivel de clasificación. El origen de estos conjuntos de datos es desconocido en la literatura85,86. | Los sistemas de triaje estadístico han existido durante ~ 10 años en contraste con los 20+ años de los sistemas de triaje expertos. Naturalmente, están menos validados63,83. |
| Sigue las pautas de mejores prácticas clínicas | El campo de la Medicina de Urgencias y Emergencias se centra en el triaje. Capaz de codificar el conocimiento experiencial adquirido en el campo18,87. | Es posible que haya patrones de clasificación que aún no han sido descubiertos por los humanos para la codificación88. | Potencial para identificar patrones de clasificación que optimicen la utilización mínima de recursos y la máxima probabilidad de resolución de síntomas18,89,90,91,92. | El triaje no tiene un «estándar de oro». Por lo tanto, no hay una «respuesta correcta» con la que etiquetar los datos de entrenamiento93. | |
| Mejora a lo largo del tiempo | Los sistemas pueden tener sus propias reglas para el triaje que varían según los recursos disponibles en las instalaciones. Los sistemas expertos permiten esta configurabilidad94. | La mejora a lo largo del tiempo requiere un muestreo aleatorio de encuentros reales de triaje y refuerzo humano. También requiere prestar atención a las distribuciones de triaje a nivel poblacional y ajustarlas según sea necesario95. | Si se proporciona retroalimentación sobre la corrección del triaje de un paciente individual, los sistemas basados en el aprendizaje automático pueden permitir una mejora más automatizada con el tiempo96,97. | No existe un conjunto estándar de datos «específicos de triaje» en el EMR. El hecho de que un paciente individual haya ido a X ubicación, no significa que fuera la ubicación «correcta» para su atención. El EMR no contiene información directa sobre si ese sitio de atención era o no «correcto» o si otro habría sido más apropiado98,99,100,101,102,103,104,105,106,107,108,109. | |
| Explicabilidad | Cualquier predicción puede ser examinada para determinar las reglas exactas que condujeron a ella y ajustarse según sea necesario110. | Si se encuentra un problema con el triaje, es difícil entender exactamente por qué se proporcionó esa recomendación y ajustar esa vía específica111. | |||
| Largura | Hace menos preguntas en general (promedio: 17.5)63. | Hace más preguntas (promedio: 29.2)63. | |||
Clasificación
Definición
El término médico para triaje proviene del verbo francés trier, que significa clasificar o separar37,38. En consecuencia, el triaje es un proceso de asignación de prioridad a los tratamientos de un paciente en función de la gravedad de su afección. Este proceso ayuda a asignar recursos médicos limitados y se utiliza en una variedad de entornos37. Después de su desarrollo y uso en tiempos de guerra, el triaje se generalizó para entornos de emergencia en la vida civil39. El triaje se utiliza habitualmente en los servicios de urgencias para determinar el orden en que se atiende a los pacientes40. De manera más general, los proveedores de atención primaria (PCP, por sus siglas en inglés) deben clasificar qué pacientes pueden ser tratados por ellos y cuáles pacientes deben ser tratados por especialistas. Si bien los hospitales o sistemas individuales pueden desarrollar sus propias reglas para apoyar la toma de decisiones de los médicos de atención primaria, no existe un conjunto estandarizado de pautas clínicas que determinen exactamente qué pacientes deben ser remitidos a especialistas41. Hoy en día, los pacientes deben decidir acceder a la atención entre una lista cada vez mayor de servicios de emergencia, salas de emergencia, centros de atención de urgencia, clínicas ambulatorias/minoristas, proveedores de telemedicina, consultorios de atención primaria, consultorios especializados y más. Como resultado, entre el 20 y el 40% del gasto sanitario se desperdicia cada año en una utilización innecesaria de la asistencia sanitaria42. Para minimizar el uso de recursos, es necesario permitir que los pacientes se autoclasifiquen mejor. La tecnología digital orientada al paciente ha hecho posible que el PDS se proporcione en formatos fáciles de usar para el paciente. Por lo general, hay dos clases de sistemas de clasificación virtual: (1) sistemas basados en reglas y (2) sistemas basados en aprendizaje automático. Cada una de estas dos clases ofrece ciertas ventajas y desventajas que se analizarán en las siguientes subsecciones.
Sistemas de autoclasificación basados en reglas
Los sistemas de triaje virtual basados en reglas emplean un conjunto de reglas empíricas, diseñadas por profesionales médicos, para guiar a los pacientes con un conjunto específico de signos, síntomas y afecciones al sitio de atención más apropiado dentro del período de tiempo más apropiado. Los hospitales o sistemas de salud individuales pueden diseñar sus propias reglas para ayudar a los médicos de atención primaria a determinar qué pacientes deben ser derivados a qué especialistas41,43. Sin embargo, el primer conjunto de reglas de triaje adoptado a nivel nacional fue para el triaje telefónico44. La mayoría de los sistemas de salud en los EE.UU. confían en los protocolos basados en reglas desarrollados por los Dres. Barton Schmitt y David Thompson para el triaje telefónico de pacientes (STPs)45. Los sistemas basados en reglas sirven para codificar el conocimiento médico y la experiencia acumulada a lo largo de la vida útil de la medicina clínica y permiten una completa configurabilidad y explicabilidad de cualquier triaje. Los STP se han utilizado en >200 millones de encuentros con centros de llamadas de enfermería45. Las desventajas de los sistemas basados en reglas son que son laboriosos de crear, requieren un proceso de reconciliación entre varios médicos, complicado por el hecho de que no existe un estándar de oro de triaje y existe una variación inherente entre la forma en que los diferentes profesionales médicos podrían clasificar a los pacientes, y que la precisión del triaje se limitaría a la precisión de los humanos que desarrollan las reglas.. Algunas soluciones han llevado a cabo este proceso de conciliación para estandarizar mejor las reglas exactas que indicarían qué pacientes deben ver a un especialista en comparación con un médico de atención primaria (Tabla 2). Estas soluciones utilizan árboles de decisión o gráficos de conocimiento para impulsar las experiencias de autoclasificación que están codificadas con las pautas de mejores prácticas clínicas tal como se han desarrollado y validado hasta la fecha (por ejemplo, STP).
Sistemas de autoclasificación basados en aprendizaje automático (ML)
A diferencia de los sistemas basados en reglas que utilizan reglas de decisión empíricas, un enfoque basado en ML para el triaje virtual depende de entrenar un modelo con un gran conjunto de datos de pacientes para predecir el sitio de atención más apropiado para que esa persona acuda. Con muchos de los enfoques estadísticos, a menudo es difícil proporcionar las respuestas exactas de los pacientes que condujeron a su resultado de triaje (por ejemplo, redes neuronales, aprendizaje profundo, basado en transformadores)47. Esto afecta a la explicabilidad e interpretabilidad de los enfoques estadísticos de aprendizaje automático (ML). Ciertos enfoques estadísticos pueden permitir cierta explicabilidad (por ejemplo, enfoques de redes no neuronales como los modelos de regresión y la importancia de las características basadas en árboles)48,49. Estas son limitaciones típicas de los enfoques basados en ML en general.
Uno de los desafíos al etiquetar conjuntos de datos para el aprendizaje supervisado es que puede ser difícil establecer una «respuesta correcta» para la clasificación. Esto se debe a que diferentes proveedores de atención médica (HCP, por sus siglas en inglés) clasificarían a ciertos pacientes de manera diferente46. Como resultado, los datos de entrenamiento disponibles están sujetos a variabilidad. Además, no hay consenso sobre la base para concluir que un paciente fue clasificado «con éxito». Numerosos centros de prestación de servicios de salud podrían resolver el problema de un paciente (Recuadro 1). Teóricamente, el autotriaje perfectamente preciso siempre indicaría al paciente el sitio óptimo de atención al menor costo. Por el contrario, una autoclasificación inexacta daría lugar a más puntos de contacto innecesarios y a un mayor coste. La mejor práctica actual en este campo del triaje son las reglas en las que se ha confiado en los centros de llamadas de enfermería durante las últimas décadas (STP). Las métricas de éxito podrían incluir el número de visitas necesarias para resolver/manejar el problema médico de un paciente o el costo de la atención brindada a los pacientes (Recuadro 1). Estas dos métricas podrían combinarse en una proporción. Sugerimos esta proporción con la idea de que una atención médica «exitosa» resolvería idealmente la inquietud médica de un paciente utilizando los recursos mínimos de atención médica para hacerlo. Usando alguna medida definida de éxito, los modelos de aprendizaje automático podrían entrenarse para recomendar ciertos niveles y tiempos de atención. A modo de ejemplo, podríamos crear un modelo que minimice las derivaciones a otros cuidados y la utilización de los recursos sanitarios.
Mostrar menos
El uso de modelos de lenguaje de gran tamaño para la autoclasificación
Noviembre de 2022 marcó un punto de inflexión en lo que era posible con la IA con el lanzamiento de ChatGPT y la posterior ola de proliferación de LLM en todas las industrias. La capacidad de los LLM para procesar y convertir entradas en salidas atractivas y similares a las humanas marcó un punto de inflexión en lo que era posible con las experiencias conversacionales automatizadas con pacientes que informaron el deseo de usar LLM para consultas relacionadas con la atención médica50.
Hasta ahora, los LLM han sido evaluados por su relación con los pacientes, su triaje y precisión DDx en general, y su utilidad para la autoeducación y el autodiagnóstico del paciente en una colección de casos de uso específicos (p. ej., COVID51, oftalmología52, apnea obstructiva del sueño53, sialendoscopia54). Sin embargo, el uso comercial de los LLM en la atención médica se ha limitado en gran medida a la documentación clínica y otras funciones administrativas del lado del proveedor. El lado de cara al paciente aún no ha demostrado el mismo nivel de adopción.
Gran parte de la lentitud en la adopción por parte del paciente se ha debido a una serie de preocupaciones con los LLM, que incluyen, entre otros, las tasas de alucinación, la consistencia de la respuesta, la interpretabilidad, la regulación y los derechos de autor55. Se descubrió que ChatGPT tenía una precisión del 63% en promedio en 10 categorías de razonamiento diferentes56. En la atención médica, el riesgo de una recomendación incorrecta tiene un costo para la salud del paciente. Por lo tanto, es imperativo que los pacientes y los profesionales de la salud tengan la capacidad de interpretar las razones exactas de la predicción/recomendación de un modelo. En general, este es un inconveniente de los enfoques de ML para el triaje o diagnóstico autoinformado por el paciente57.
Considerable work is being done to evaluate the full scope of LLMs’ viability in healthcare. Levine et al. compararon la precisión del triaje y el diagnóstico de GPT-3 con un conjunto estandarizado de viñetas utilizadas históricamente para evaluar la precisión de los sistemas de autotriaje. GPT-3 realizó diagnósticos a niveles cercanos, pero inferiores a los de los médicos y mejores que los de los profanos. El modelo tuvo un desempeño menos bueno en el triaje, donde su desempeño estuvo más cerca del de los legos y por debajo del de los clínicos58. Hirosawa et al. evaluaron la precisión diagnóstica de los diagnósticos diferenciales generados por GPT-3 en una colección de quejas principales comúnmente reportadas y encontraron que GPT-3 es un 40% menos preciso en promedio en comparación con el juicio de los médicos59. Chiesa-Estomba et al. evaluaron el potencial de GPT-3 como herramienta de apoyo para la toma de decisiones clínicas en sialendoscopia y el apoyo a la información al paciente. Se encontró que GPT-3 tiene una fuerte concordancia con los especialistas en otorrinolaringología54. Cuando se compararon las respuestas a las preguntas de los pacientes de GPT-3 con las de los médicos, los pacientes informaron que las respuestas del LLM fueron un 10× más empáticas que las de los médicos60. Además, los pacientes encuestados indicaron el deseo de utilizar los LLM para consultas relacionadas con la atención sanitaria50. Con todo, los LLM tienen un progreso significativo que hacer para lograr una precisión comparable a la de los médicos en casos de uso de autotriaje y autodiagnóstico, han demostrado una clara demanda de los pacientes y han superado a los médicos en la empatía de sus respuestas. Dejando a un lado la regulación, existe un claro potencial para el uso de LLM en los espacios de autotriaje y autodiagnóstico.
Panorama regulatorio de la FDA
Actualmente, los sistemas de apoyo a la toma de decisiones que hacen uso de los datos autoinformados por los pacientes no están regulados por la FDA. Sin embargo, la FDA ha publicado varias iteraciones de borradores de directrices que han estado abiertas a comentarios públicos 36. A través de estas iteraciones ha habido varios desarrollos. Inicialmente, el borrador de las directrices separaba el SPD y los sistemas de apoyo a la decisión clínica (CDS) como dos categorías diferentes61. Sin embargo, estas dos categorías se han fusionado ahora en una categoría más amplia de CDS36. Los CDS son aquellos que cumplen con los siguientes cuatro criterios: El sistema «(1) no está destinado a adquirir, procesar o analizar una imagen médica o una señal de un dispositivo de diagnóstico in vitro o un patrón o señal de un sistema de adquisición de señales (2) está destinado a mostrar, analizar o imprimir información médica sobre un paciente u otra información médica (3) está destinado a apoyar o proporcionar recomendaciones a un profesional de la salud sobre la prevención, el diagnóstico o el tratamiento de una enfermedad o afección y (4) tiene el propósito de permitir que un profesional de la salud revise de forma independiente la base de las recomendaciones que presenta dicho software, de modo que no sea la intención que el profesional de la salud se base principalmente en cualquiera de dichas recomendaciones para hacer un diagnóstico clínico o una decisión de tratamiento con respecto a un paciente individual36.
Los sistemas que se ajustan a estos cuatro criterios están exentos de la regulación de la FDA. Tenga en cuenta que el último de estos criterios tiene implicaciones importantes en la arquitectura de los sistemas de clasificación y DDx exitosos. Permitir que los pacientes vean la base por la cual se les recomienda la información es más difícil para los sistemas que operan con un enfoque de ML en comparación con los que se basan en reglas. Si el enfoque específico de ML no puede ajustarse a este cuarto criterio, entonces no estaría exento de la regulación de la FDA y estaría sujeto a un mayor escrutinio. Esto requeriría mayores recursos para llevar con éxito los sistemas basados en ML para su uso generalizado con los pacientes. En caso de que el borrador de las directrices de apoyo a las decisiones clínicas de la FDA se convierta en ley, los sistemas híbridos o basados en normas pueden tener una ventaja desde el punto de vista regulatorio. Una limitación de esta revisión es su enfoque en el sistema de salud de los Estados Unidos. No incluye una visión general de la reglamentación de otras regiones del mundo que pueda ser objeto de trabajos futuros.
Desafíos y rumbos futuros
La generalización de la IA a la práctica clínica sigue siendo una incógnita62. En la literatura se han reportado muchos modelos diferentes de ML por su capacidad para superar a los humanos en entornos médicos, sin embargo, pocos se han generalizado para un uso clínico amplio62. A menudo, estos modelos no funcionan tan bien cuando se generalizan a la población en general. Nuestra hipótesis es que los enfoques más exitosos emplearán una metodología híbrida de conocimiento empírico y métodos estadísticos. En pocas palabras, el uso de los siglos de experiencia médica humana para codificar reglas que generalmente son aceptadas por la mayoría de los expertos médicos probablemente permitiría que los sistemas alcancen niveles de precisión comparables a los clínicos humanos. Luego, la construcción de capas estadísticas sobre estas reglas empíricas permitiría a los sistemas avanzar en la precisión más allá de la capacidad humana y, al mismo tiempo, permitir más experiencias conversacionales.
Los datos publicados sobre el rendimiento de los sistemas de autoclasificación son limitados. El artículo seminal que comparó la precisión de varios sistemas de diagnóstico y triaje estadísticos y basados en el conocimiento encontró que, entre 23 verificadores de síntomas, el diagnóstico correcto se proporcionó primero en el 34% (IC: 3%) de un conjunto de viñetas de pacientes estandarizadas, en los 20 diagnósticos principales en el 58% (IC: 3%) de las viñetas, y el triaje apropiado en el 57% (IC: 5%) de viñetas63. Un estudio posterior que comparó 37 sistemas reportó resultados similares64. El rendimiento del triaje disminuyó con la urgencia decreciente de la condición63. La precisión de los sistemas de triaje para escenarios emergentes fue de 2 a 3× mayor que en escenarios de autocuidado63. Por otra parte, la precisión varió ampliamente como El rendimiento en los consejos de triaje adecuados de 24 verificadores de síntomas varió del 33 al 90%63,64,65.
Esta amplia variación en la precisión de los sistemas de auto-triaje revela una de sus limitaciones. Es posible que la autoevaluación inexacta aumente los puntos de contacto totales y el costo. Para ilustrar este punto, se puede llevar a cabo un experimento mental con los siguientes grupos: (a) usuarios de un sistema de auto-triaje «ficticio» que asigna aleatoriamente un triaje a cada paciente y (b) usuarios de un sistema de auto-triaje «perfecto» que es capaz de optimizar perfectamente todos los factores de precisión clínica, seguro, preferencias del paciente, preferencias del proveedor y preferencias de la red. Una hipótesis es que los usuarios de (a) son rebotados en el sistema con más frecuencia. Posiblemente hasta que tengan la suerte de estar con el proveedor adecuado para su necesidad. Por el contrario, a los usuarios de (b) siempre se les presentaría el proveedor exacto para su necesidad clínica inmediata, minimizando así el número de puntos de contacto, el costo y el tiempo invertido para recibir esa atención óptima. Aún no se ha informado sobre el efecto de los sistemas de auto-triaje en el promedio # de puntos de contacto con el paciente en el sistema de salud, el costo promedio de la atención general o en los resultados clínicos. En cualquier caso, cualquier estudio que examine estos resultados del autotriaje también tendrá que tener en cuenta la variación en la precisión en función del sistema de triaje individual utilizado.
Un estándar de oro de la precisión del triaje es el juicio de los médicos humanos. Existen estudios que evalúan la concordancia de los sistemas de auto-triaje y diagnóstico con los profesionales médicos. Se ha encontrado que varios sistemas con capas basadas en reglas y ML funcionan al menos tan bien como los médicos46,66. A medida que se prueban más métodos estadísticos, los sistemas de auto-triaje y diagnóstico continúan mejorando. Un grupo planteó la hipótesis de que los médicos pasan más tiempo descartando que dentro. Así, se encontró que un sistema contrafáctico es más preciso que uno inferencial67. Además, a medida que se cree una mayor conectividad entre estos sistemas y la historia clínica electrónica (EMR), aumentará la retroalimentación. Los sistemas de auto-triaje pueden comenzar a optimizarse para obtener referencias y costos mínimos, al tiempo que maximizan la resolución y la satisfacción. Están surgiendo sistemas híbridos basados en reglas y ML46. Eventualmente, la integración con la tecnología portátil y de sensores facilitará la incorporación de información objetiva sobre el estado de salud de una persona, mejorando aún más la precisión. Comprender las compensaciones entre varios métodos basados en reglas y ML será fundamental para diseñar sistemas PDS autoguiados exitosos. Además, navegar por el panorama regulatorio emergente también determinará el éxito. La investigación y el diseño de la experiencia del usuario (UX) para optimizar la forma en que los usuarios pacientes interactúan con los sistemas de auto-triaje serán críticos. Teniendo en cuenta que los sistemas de auto-triaje requieren cantidades significativas de información (decenas de preguntas) para ser respondida por los pacientes usuarios, hay un alto porcentaje de abandono. La optimización de la experiencia de usuario para facilitar y maximizar la finalización representa un cuerpo emergente de literatura.
Una de las modalidades más comunes para administrar sistemas de auto-triaje es a través de un chatbot 6,9,63,68. La investigación sobre el diseño y la optimización de los chatbots de atención médica ha identificado varias ideas clave para mejorar la participación de los usuarios y minimizar las tasas de abandono. En los entornos sanitarios, la percepción de empatía y comprensión de un chatbot puede hacer que los usuarios se sientan más cómodos69. Además, las investigaciones destacan la importancia de la equidad en las respuestas de los chatbots. Un estudio indica que los usuarios son sensibles a los sesgos percibidos o a la injusticia en las interacciones de los chatbots70. Garantizar la transparencia y la equidad en el comportamiento de los chatbots se correlaciona directamente con una mayor satisfacción y confianza, lo que subraya la necesidad de principios de diseño éticos en el desarrollo de UX para los sistemas de atención médica71. Además, la presentación visual y el estilo conversacional de los chatbots también pueden influir en la forma en que los usuarios perciben e interactúan con el sistema, aunque estos factores no siempre pueden mejorar directamente la experiencia del usuario sin una integración reflexiva.
Para reducir las tasas de abandono en los sistemas de autoevaluación, las mejores prácticas de la investigación sobre chatbots sugieren centrarse en la creación de interacciones fluidas e intuitivas que reduzcan la carga cognitiva sin dejar de recopilar información esencial72. Esto incluye la optimización de la longitud y la complejidad de las preguntas y el diseño de agentes conversacionales que puedan adaptarse a las respuestas de los usuarios de forma dinámica, manteniendo la interacción atractiva y eficiente70. El potencial de diseños más efectivos y centrados en el ser humano radica en equilibrar estos factores tecnológicos y psicológicos para crear una experiencia que se sienta personalizada y receptiva.
Para garantizar que la experiencia también sea segura, hay que tener en cuenta una serie de cuestiones éticas y de privacidad. En primer lugar, la protección de la privacidad del paciente es primordial. Estos sistemas recopilan y analizan datos de salud confidenciales y, por lo tanto, deben cumplir con estrictos estándares de seguridad de datos. Estos incluyen la prevención del almacenamiento de información de salud identificable, el borrado automatizado de datos, la auditoría de los procesos y datos de la organización y la certificación de mantener estrictos estándares de seguridad (por ejemplo, HIPAA, SOCII o HITRUST). Además, los usuarios deben tener control sobre cómo se recopila y utiliza su información, garantizando el consentimiento informado y la autonomía en las decisiones sanitarias73. Igualmente importante es la necesidad de garantizar que los sistemas de autoclasificación funcionen de manera equitativa. Estas herramientas deben diseñarse para tener en cuenta las desigualdades sistémicas, como las que enfrentan las personas con discapacidad o las que no lo son.Entornos socioeconómicos desfavorecidos. La incorporación de ajustes de equidad, como reservar la atención para grupos marginados, ayuda a mitigar los sesgos en la toma de decisiones algorítmicas74,75.
La transparencia es otra consideración ética crítica. Proporcionar a los pacientes usuarios y a los profesionales de la salud la capacidad de comprender la lógica que subyace a las decisiones tomadas por los algoritmos de autoclasificación genera confianza y garantiza un uso adecuado76. Hacerlo también se alinea con el borrador de la guía de la FDA36. Sin información clara y accesible sobre el funcionamiento de estos sistemas, existe el riesgo de desconfianza o uso indebido, lo que puede conducir a resultados perjudiciales para los pacientes77. Por último, si bien los sistemas de autotriaje pueden mejorar la eficiencia, los profesionales de la salud deben ser capaces de intervenir cuando sea necesario para corregir errores algorítmicos o sesgos, asegurando que las decisiones críticas de salud no se dejen completamente en manos de sistemas automatizados74,78.
Abordar estas cuestiones éticas (privacidad, equidad, transparencia y supervisión humana) permitirá que los sistemas de autoclasificación contribuyan positivamente a la prestación de atención médica, sin exacerbar las desigualdades existentes ni socavar la confianza de los usuarios. La intersección de los datos autoinformados de los pacientes, la inteligencia artificial y la investigación de la experiencia del usuario en forma de sistemas de autotriaje representa un paso importante hacia una prestación de atención sanitaria más proactiva, automatizada, optimizada y autoguiada.
Pero para lograr este futuro, es probable que se requiera una colaboración más profunda entre los socios de la industria, incluidas las compañías de registros médicos electrónicos, los sistemas de salud comunitarios, los pagadores y las empresas de tecnología. Esto se debe a que la precisión de los sistemas de auto-clasificación es limitada sin una «respuesta correcta» para afirmar o negar la validez de una recomendación. Sin embargo, sin acceso a los datos que se encuentran en el EMR o en las declaraciones, no hay forma de «cerrar el ciclo» con fines de validación. Esta necesidad insatisfecha en el campo da como resultado un progreso más lento para mejorar la experiencia de navegación del paciente en la atención médica. Las colaboraciones entre estos socios resolverían esto. Si bien los centros médicos albergan la mayoría de los datos que se requerirían para validar dichos sistemas, la mayor parte de la innovación en los sistemas de autotriage de IA se ha producido en la industria privada (Tabla 3).
Adopción de sistemas de autotriage por parte del sistema de salud
Como parte de esta revisión, se midió la adopción del auto-triage por parte de los sistemas de salud en los EE. UU. (Tabla 3 y 4). Se examinaron los sitios web de 647 sistemas de salud aplicando los siguientes criterios de inclusión de una lista completa de hospitales y sistemas de salud de EE. UU79: (a) el sistema posee al menos 3 hospitales y genera al menos 250 millones de dólares en ingresos netos de pacientes, (b) el sistema tiene una experiencia web distinta, y (c) la experiencia de auto-triaje está disponible para el público. De esta lista, se encontró que 50 sistemas de salud (7,72%) adoptaron 15 sistemas diferentes de autotriage, y 6 de ellos (0,93%) fueron de autotriage exclusivamente para COVID. De los 15 sistemas de autoevaluación, el proveedor más ampliamente adoptado estaba disponible en los sitios web de 13 sistemas de salud (2,01%) y el siguiente más alto estaba disponible en 10 sistemas de salud (1,55%) cada uno (Tabla 3). Dado que los sistemas de salud de EE. UU. varían en tamaño, también se incorporó al análisis el número de hospitales atendidos por cada sistema de salud. La Tabla 4 muestra que 534 hospitales (8,73% de un total de 6120 en los EE.UU.)80) tienen sitios web con auto-clasificación fácilmente disponibles. El proveedor más adoptado estuvo disponible en los sitios web que representan a 244 hospitales (3,99%). El siguiente más alto está disponible en los sitios web que representan a 91 hospitales (1,49%). Un estudio futuro podría examinar las diferencias en las necesidades de enrutamiento necesarias para que la tecnología optimice el acceso de los pacientes con la entrega de recursos de atención médica a diferentes escalas del área de servicio (por ejemplo, 100 hospitales frente a 300 hospitales). Además, en la Tabla 2 se proporcionan más detalles sobre cada sistema.
Tabla 4 Adopción hospitalaria de soluciones de triage virtual por parte del proveedor en sitios web accesibles al público (no autenticados)
Por ahora, la mayoría de los pacientes que experimentan un nuevo síntoma deben autoclasificarse en un sitio de atención adecuado. Como resultado, un estudio muestra que el 60% de las veces los pacientes se clasifican a sí mismos de manera inapropiada81. A gran escala, se estima que se desperdicia casi un billón de dólares de gasto sanitario (es decir, el 25% del gasto total en atención sanitaria)82. Los sistemas de autotriage son muy prometedores para ayudar a los pacientes a tomar decisiones más precisas desde el punto de vista clínico. De hecho, el mismo estudio mostró que entre el 15 y el 30% de los pacientes que utilizaron un sistema de autotriage digital se comprometieron con los resultados del triage para redirigirlos a una atención más adecuada desde el punto de vista clínico81.
A medida que los sistemas de salud, los pagadores, las compañías de EHR y las compañías de auto-triaje trabajan más juntos, las asociaciones entre ellos beneficiarían a los pacientes al proporcionar un «circuito cerrado» de retroalimentación a los sistemas de IA. De este modo, estos sistemas podrían validar las predicciones y aprender más rápidamente con un mayor uso; en última instancia, proporcionando capacidades de navegación más inteligentes. Como resultado, menos pacientes rebotarían en el sistema de salud y más probablemente buscarían la atención adecuada en el lugar y el momento adecuados. Además, hacerlo también beneficiaría a los pagadores, ya que una utilización más eficiente de la atención médica reduciría el costo de la atención por paciente.
Finalmente, los proveedores podrían esperar ver a más pacientes que sean apropiados para ellos. Esto es especialmente relevante en el contexto de la actual escasez de proveedores y el agotamiento. Más que nunca, el sistema sanitario necesita asegurarse de que no está desperdiciando recursos innecesarios. Permitir que los pacientes se encaucen mejor es un componente clave para controlar el gasto. Se vislumbra un futuro en el que los conocimientos necesarios para la toma de decisiones clínicamente precisas se democraticen y se hagan accesibles a los pacientes en una experiencia agradable que beneficie a la gente común, independientemente de su nivel educativo.
