
La inteligencia artificial contiene los conceptos de machine learning y deep learning, donde el machine es aprendizaje automatizado y el deep, aprendizaje profundo. El concepto de inteligencia artificial surge en la década del cincuenta con la idea de automatizar tareas que realizaban los humanos. la inteligencia artificial es la capacidad de las maquinas de usar algoritmos, aprender de los datos y utilizar lo aprendido en la toma de decisiones tal y como lo haría un ser humano.
El machine learning es la forma tradicionalmente desarrollada mediante algoritmos de regresión y con árboles de decisión, el deep learning lo hace con redes neuronales. Ambos desarrollan aprendizajes supervisados por personas, o no, por experiencias acreditadas o no, un sistema de aprendizaje no supervisado se basa en algoritmos que aprenden datos con elementos no etiquetados o buscando patrones y relaciones. El aprendizaje no supervisado no requiere intervención humana. Los algoritmos de aprendizaje no supervisado pueden ser de clustering (clusterización o agrupación), es decir, descubrimiento de grupos en los datos, como, por ejemplo, agrupación de clientes según sus compras, y de asociación, o sea el descubrimiento de reglas dentro del conjunto de datos. Por ejemplo, sirven para descubrir qué clientes de los que compran un coche también contratan un seguro.
En cambio, un sistema supervisado se basa en algoritmos que aprenden de datos con elementos etiquetados. Se facilitan los datos de entrada y de salida esperados. Este tipo de aprendizaje necesita intervención humana.
Respecto a los modelos de aprendizaje supervisado, estos requieren una mayor intervención humana pues se usan como input datos que han sido previamente etiquetados. Es decir, el modelo conoce el input y el output y aprende, a partir de estos, patrones que le permiten la aplicación a otros datos cuya solución se desconozca. Se12puede hablar así de un aprendizaje a través de ejemplos, y de ahí la importancia de la
medición del error o evaluación de la performance del modelo.
De esta forma, tres son los elementos básicos de los modelos de Machine Learning que aplican aprendizaje supervisado (Tamir, 2020):
1.Proceso de decisión: trata de hallar los patrones en los datos que son clave para realizar la tarea.
2.Función de error: Para conocer la performance 8del modelo. Algunos ejemplos de funciones de pérdida son RMSE (Root Mean Square Error), MAPE (Mean Absolute Porcentual Error), MAE (Mean Absolute Error) y entropía cruzada binaria o multiclase y hinge loss (para modelos de clasificación).
3.Proceso de optimización del modelo: se ajusta y actualiza el modelo para mejorarlo en
mayor o menor medida dependiendo del error detectado.
En este caso, los algoritmos pueden ser de clasificación, para clasificar objetos dentro de clases, como, por ejemplo, pacientes enfermos o correo spam, o de regresión, para predecir un valor numérico como puede ser el precio de una casa, la demanda de ocupación, el peso o la altura.
La AI ha desarrollado otras ramas desde su aparición, como el procesamiento del lenguaje natural (natural language processing, NLP), la robótica o el reconocimiento de imágenes o del habla (speech and image recognition, and machine vision), entre otras.
El deep learning DL forma parte de lo que se conoce como apredizaje automático, se acerca más a la forma en la que aprendemos los humanos, veremos que hay dos tipos de redes neuronales convolucionales y recurrentes.
2.1 INTRODUCCIÓN
L. Dharani y G. Victo Sudha George
En el mundo moderno, las personas tienen diferentes vidas y comportamientos, incluidas diferentes dietas y hábitos alimenticios, que pueden ser poco saludables. Utilizamos una serie de algoritmos automatizados para la detección y el tratamiento de enfermedades con el fin de prevenir este problema de salud. En los últimos años, el aprendizaje profundo ha tenido un impacto sustancial en varios campos científicos.
Los algoritmos de aprendizaje profundo (DL) superaron a los métodos de vanguardia en una serie de aplicaciones, incluido el procesamiento y el análisis de imágenes, lo que lo demostró. El aprendizaje profundo también funcionó mejor que los intentos anteriores al lograr resultados de vanguardia en tareas como los automóviles autónomos.
El aprendizaje profundo incluso ha superado a los humanos en varias tareas, como el reconocimiento de objetos y los juegos. Otro campo en el que este desarrollo tiene un gran potencial es la medicina. Debido al cambio hacia la terapia personalizada y la acumulación de grandes cantidades de información y datos del paciente, existe una necesidad apremiante de procesamiento y análisis de datos de salud confiables y automatizados.
La información del paciente es obtenida por médicos generales, aplicaciones móviles de atención médica y portales en línea, por nombrar algunos, además de lugares clínicos como hospitales. En los últimos años se ha producido una nueva oleada de importantes proyectos de investigación como consecuencia de esta tendencia.
En el segundo trimestre de 2020, PubMed devolvió casi 11.000 artículos con la frase «aprendizaje profundo», y casi el 90% de estos artículos procedían de los tres años anteriores.
A pesar de ser uno de los principales motores de búsqueda de información médica, PubMed no engloba todos los artículos relacionados con la medicina. Como consecuencia, obtener una comprensión profunda del tema del «aprendizaje profundo médico» y acceder a revisiones exhaustivas en campos relacionados es cada vez más difícil. Sin embargo, recientemente se han publicado una serie de revisiones y publicaciones de investigación sobre el aprendizaje profundo médico. Tienden a especializarse en un área de la medicina, como el examen de fotografías médicas que muestran una sola enfermedad. Con estas encuestas como punto de partida, con esta publicación, esperamos dar la primera meta-revisión exhaustiva de las encuestas médicas de aprendizaje profundo
2.2 MACHINE LEARNING CONOCIMIENTO PROFUNDO
El conocimiento profundo es una técnica de IA/ML que intenta imitar la forma en que los humanos aprenden nueva información. Junto con la visualización de datos y análisis, el conocimiento profundo es una piedra angular de la ciencia de datos. La mayoría de las personas lo clasifican como un subconjunto del aprendizaje automático [1]. La base de esta área es la superación personal y el autoaprendizaje a través del estudio de algoritmos informáticos. Por lo general, una computadora utiliza imágenes, manuscritos o una amplia gama de conocimientos profundos para realizar tareas de clasificación. Los algoritmos de aprendizaje profundo pueden superar el rendimiento humano en precisión de primera línea. La tecnología detrás del aprendizaje profundo se encuentra en el núcleo de los bienes y servicios comunes. Las limitaciones de la potencia de los ordenadores habían limitado previamente la complejidad de las redes neuronales [2]. Por otro lado, las mejoras en el análisis de big data han hecho posible que los procesadores monitoreen, comprendan y respondan a estados complejos más rápidamente que los individuos. El aprendizaje profundo ha sido útil para el reconocimiento de voz, la traducción de idiomas y la categorización de imágenes.
2.2.1 Conocimiento profundo vs conocimiento automático Si el aprendizaje profundo es una división del aprendizaje automático, ¿en qué se diferencian entre sí? En términos de los tipos de datos que utiliza y las técnicas que emplea para aprender, el conocimiento profundo es diferente del conocimiento obsoleto de la máquina [1], como se muestra en la Figura 2.1. Los sistemas de aprendizaje automático generan predicciones a partir de
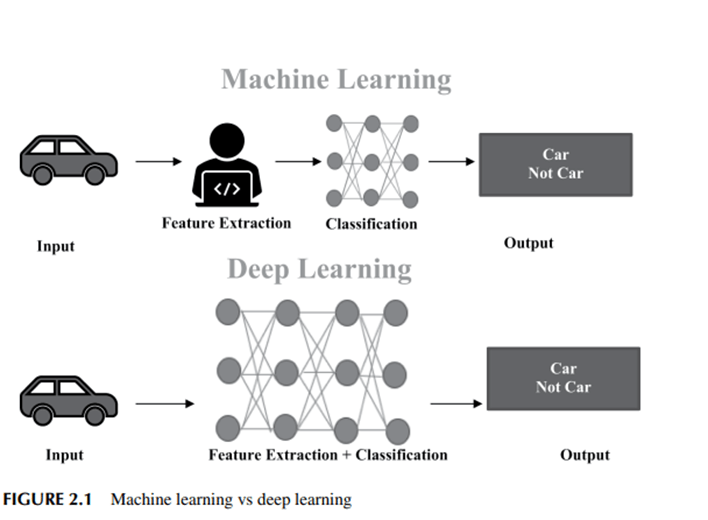
Datos, en los que se han especificado propiedades específicas de los datos de entrada del modelo y se organizan en tablas. Esto no significa que siempre evite el uso de entradas no estructuradas; Más bien, si lo hace, normalmente gasta energía haciendo un poco de preprocesamiento y poniéndolo en un formato planificado previamente.
2.2.2 Funcionamiento básico
Un niño que aprende a reconocer a un perro pasa por el mismo procedimiento que realizan los algoritmos informáticos de aprendizaje profundo. Después de aprender de los datos, cada algoritmo de la jerarquía aplica una transformación en línea a esos datos y produce un modelo estadístico. El proceso se repite hasta que el resultado alcanza un nivel aceptable de precisión. Debido a la complejidad del procesamiento de datos involucrado, el aprendizaje profundo se inspiró en este hecho. Al igual que el aprendizaje automático típico, este enfoque requiere una configuración supervisada, y el programador debe ser extremadamente explícito sobre los criterios que debe usar para determinar si una imagen representa o no a un perro. El método de extracción de características lleva mucho tiempo. El primer paso es proporcionar a la computadora algunos datos de entrenamiento, como un conjunto de imágenes etiquetadas como «perro» o «no perro» usando metaetiquetas. Utilizando la información recopilada durante el paseo, la computadora formula un conjunto de características para el perro y desarrolla un modelo de predicción [3]. En este caso, un perro podría ser cualquier cosa en la imagen con cuatro patas y una cola, de acuerdo con el modelo inicial de la computadora. Naturalmente, los términos «cuatro patas» y «cola» son ajenos al programa. Solo se examinarán los patrones de píxeles en los datos digitales. Con cada iteración, la complejidad y la precisión del modelo de predicción aumentan. Dado un conjunto de entrenamiento, el software informático que emplea técnicas de aprendizaje profundo puede clasificar de forma rápida y precisa millones de fotos para encontrar las que tienen perros. Por el contrario, a un niño pequeño le puede llevar varias semanas o meses comprender la idea de un perro. Antes del uso de la computación en la nube y el big data, los programadores carecían de la capacidad de procesamiento y de los grandes volúmenes de datos de entrenamiento necesarios para que los sistemas de aprendizaje profundo funcionaran con un nivel aceptable de precisión. El software de aprendizaje profundo puede generar modelos estadísticos intrincados a partir de sus propios resultados, lo que permite el desarrollo de modelos de predicción precisos a partir de cantidades masivas de datos no estructurados y no etiquetados, como se muestra en la Figura 2.2. Es crucial en este punto debido a la explosión de los dispositivos de Internet de las cosas (IoT).
2.2.3 ¿Por qué el aprendizaje profundo? En pocas palabras, precisión.
La precisión del crédito es ahora más precisa que nunca gracias al aprendizaje dee. Es esencial para aplicaciones que requieren altos niveles de seguridad, como los vehículos sin conductor, y avanza en la tecnología de circuitos integrados del cliente. En algunas tareas, incluida la clasificación de objetos en imágenes, los avances recientes en el aprendizaje profundo lo han llevado al punto en que ahora supera a los seres humanos. Por ejemplo, el número de rasgos de rendimiento podría justificar la necesidad de DL.
Enfoque universal del aprendizaje: El aprendizaje universal es otro nombre para la enseñanza a distancia, que sobresale en casi todos los dominios de aplicación.

Fortaleza: Los enfoques de DL generalmente no requieren características cuidadosamente diseñadas. En cambio, los mejores rasgos se seleccionan automáticamente en relación con el trabajo en cuestión. Por lo tanto, los datos de entrada son resistentes a las modificaciones comunes.
Generalización: Técnicas de aprendizaje a distancia que utilizan el aprendizaje por transferencia (TL), que se trata en la siguiente sección, aplicadas a muchos tipos de datos o aplicaciones. Además, funciona bien cuando hay pocos puntos de datos.
Escalabilidad: DL escala bastante bien. ResNet, desarrollado por Microsoft, se utiliza normalmente a escala de superordenador; Contiene 1202 capas. La gran empresa Lawrence Livermore National Laboratory (LLNL), que se centra en nuevos marcos de red, empleó una estrategia similar que se puede implementar. Aunque el concepto de aprendizaje profundo se introdujo por primera vez en la década de 1980, no fue hasta hace poco que se hizo factible. En una red neuronal profunda como se muestra en la Figura 2.3, utilizando una gran cantidad de datos etiquetados entrenados, se requieren millones de imágenes y cientos de horas de video, por ejemplo, para crear un automóvil sin conductor. Se necesita mucha potencia informática para ejecutar programas de aprendizaje profundo. El diseño paralelo de las GPU modernas de alto rendimiento es muy adecuado para las tareas de aprendizaje profundo. Esto ayuda a los equipos de desarrollo a ahorrar hasta un 50 % la cantidad de tiempo que se tarda en entrenar redes de aprendizaje profundo cuando se utilizan junto con clústeres o computación en la nube.
El aprendizaje se introdujo por primera vez en la década de 1980, no fue hasta hace poco que se hizo factible. En una red neuronal profunda como se muestra en la Figura 2.3, utilizando una gran cantidad de datos etiquetados entrenados, se requieren millones de imágenes y cientos de horas de video, por ejemplo, para crear un automóvil sin conductor. Se necesita mucha potencia informática para ejecutar programas de aprendizaje profundo. El diseño paralelo de las GPU modernas de alto rendimiento es muy adecuado para las tareas de aprendizaje profundo. Esto ayuda a los equipos de desarrollo a ahorrar hasta un 50 % la cantidad de tiempo que se tarda en entrenar redes de aprendizaje profundo cuando se utilizan junto con clústeres o computación en la nube.

2.3 ALGORITMOS DE APRENDIZAJE PROFUNDO
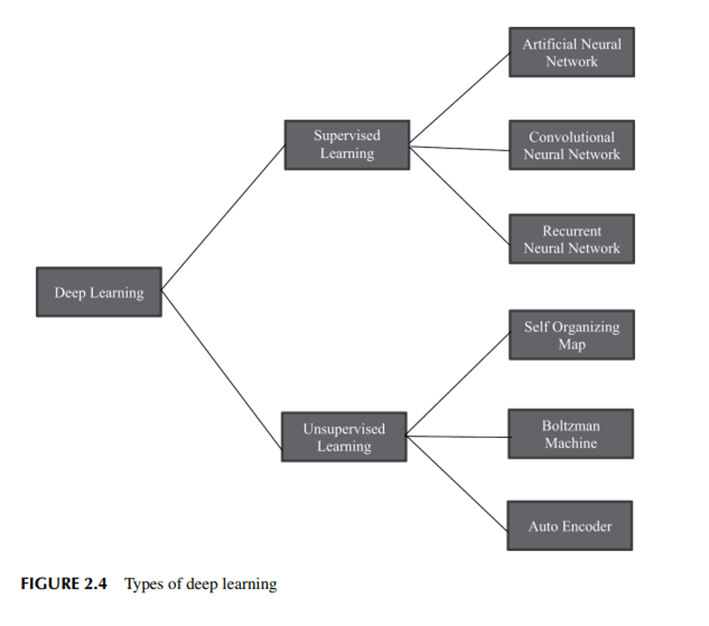
Las técnicas de aprendizaje profundo se basan en las RNA para procesar la información de forma similar a como lo hace el cerebro, al tiempo que utilizan representaciones de autoaprendizaje. A través de la fase de guía, los algoritmos utilizan la distribución indefinida de la clave en los componentes para eliminar características y clasificar cosas, así como la búsqueda de patrones de información interesantes. Esto ocurre a través de múltiples capas dentro de los algoritmos que construyen los modelos, similar a enseñar a los robots a desarrollar sus propias redes de toma de decisiones que están preentrenadas para cumplir tareas específicas. En los modelos de aprendizaje profundo se utilizan muchos algoritmos diferentes. Si bien ninguna red es a prueba de fallos, algunos algoritmos son más apropiados para llevar a cabo tareas específicas. La clasificación de los algoritmos de aprendizaje profundo se muestra en la Figura 2.4
2.4 REDES NEURONALES CONVOLUCIONALES (CNN)
CNN es el algoritmo más popular y conocido en el espacio DL. El principal beneficio de CNN sobre sus predecesores es que completa la tarea sin asistencia humana, reconociendo automáticamente los componentes relevantes. Las CNN han encontrado aplicaciones generalizadas en una variedad de dominios, desde la visión por computadora y el procesamiento de audio hasta la identificación facial y más. Las neuronas presentes en la inteligencia de la naturaleza humana y de otro tipo sirvieron de inspiración para las CNN, que tienen una estructura que se asemeja a una red neuronal típica. Específicamente, la CNN está diseñada para parecerse a la compleja estructura celular de la corteza de ilustración en el cerebro de un gato [4]. Representaciones similares, interacciones dispersas y compartición de parámetros se citan como tres ventajas de la CNN. A diferencia de las redes tradicionales totalmente conectadas (FC), CNN hace un uso completo de las estructuras de datos de entrada de la red, como el letrero visual, mediante la utilización de pesos compartidos y conexiones locales. Esto es posible gracias a la arquitectura única de CNN. Debido a que emplea un conjunto manejable de parámetros, esta técnica no solo facilita el entrenamiento, sino que también hace que la red se ejecute más rápidamente.

La altura (m), la anchura (m) y la profundidad (m) son las tres dimensiones de la entrada x de cada capa para un modelo CNN. En términos métricos, la anchura (m) es proporcional a la altura (m) (m). El nivel de profundidad es equivalente al número de canal en la televisión. La profundidad(r) de una imagen RGB típica es 3, por ejemplo. La opción de filtro de cada capa convolucional, designada por la letra k, tiene un total de tres dimensiones (n, n, qn, qn), sin embargo, en este caso, n debe ser menor y q debe coincidir o ser menor que r. Además, los kernels actúan como bloques de construcción para las conexiones locales, que crean k mapas de características de tamaño (mn1mn1) utilizando las mismas entradas (bias bk y weight Wk). Ya se dijo que cada uno está convolucionado con el insumo. La capa de convolución, similar a la utilizada en el procesamiento del lenguaje natural (NLP), produce un producto escalar entre su entrada y los pesos siguiendo el formato de la Ecuación 2.1. Por otro lado, las entradas en este escenario son réplicas a escala reducida de la fotografía original [5]. Los resultados que se presentan a continuación se obtienen aplicando una producción de función no lineal de la capa de convolución.
La Figura 2.5 muestra la arquitectura CNN para la clasificación de imágenes. HK = * f(Wk x + = bk) hk f(Wk x * + bk) (2.1) Después de eso, hacemos una operación de muestreo descendente en cada mapa de características que está presente en las capas de submuestreo subyacentes. El problema de sobreajuste puede resolverse con el tiempo, y el entrenamiento más rápido es posible al reducir el número de parámetros de red. La función de agrupación se aplica a una región vecina con el tamaño p para todos y cada uno de los mapas de características, donde p es el tamaño del kernel (como máximo o promedio). Una vez que se han obtenido las características de nivel intermedio y bajo, los niveles de FC, similares a la capa final en una red neuronal normal, suministran la abstracción de alto nivel. Las puntuaciones para la clasificación las proporciona la última capa, que puede emplear métodos como máquinas de vectores de soporte (SVM) o SoftMax. La puntuación de una determinada instancia proporciona una indicación de la probabilidad de que la clase esté presente en esa instancia.
2.4.1 Ventajas de usar CNN
La función de reparto de peso de CNN ayuda a generalizar y prevenir el sobreajuste al reducir los parámetros de red entrenables. Cuando la capa para la extracción de entidades y la capa para la clasificación se enseñan al mismo tiempo, la salida del modelo está muy controlada y depende significativamente de las entidades que se extrajeron.
2.5 REDES DE MEMORIA A CORTO PLAZO (LSTM)
Las redes neuronales recurrentes (RNN) que hacen uso de LSTM son capaces de aprender y recordar dependencias de larga duración. La retención de memoria a largo plazo de información anterior es el comportamiento predeterminado. La información se conserva a lo largo del tiempo mediante LSTM. Tener la capacidad de recordar entradas pasadas los hace efectivos en la previsión de series temporales. Cuatro capas interconectadas trabajan juntas para formar una estructura similar a una cadena en los LSTM. Con el fin de comunicarse de una manera única, los LSTM tienen varias aplicaciones más allá de la predicción de series temporales, incluido el reconocimiento de voz, la creación de música y el estudio de drogas.
2.5.1 ¿Cómo funcionan los LSTM?
Comienzan por perder el rastro de la información inútil de la situación anterior. A continuación, generan algunos de los usos del estado de la celda después de actualizar los datos del estado de la célula de forma selectiva.
Puerta de entrada: La puerta de entrada selecciona los valores de entrada que se utilizarán para modificar el contenido de almacenamiento de la memoria. Puerta de entrada: La función sigmoide determina si se debe pasar a través de datos 0 o 1. La función tan también añade más peso a la información que se ha proporcionado, asignando una calificación de importancia a un tamaño que va de -1 a i W . [h bi C W h x b t i t t C t t C ( ] ) tanh ( .[ , ] ) xt 1 Overlook Gate: Reconoce datos extraíbles por bloques. La elección se realiza mediante la función sigmoide. Considera que el estado anterior (ht-1), la entrada (xt) y el estado de celda Ct-1 dan un número entre 0 y 1. f W . [h b t f t f ( ] x ) t Puerta de salida: El rendimiento del bloque depende de la entrada y de la memoria. La función sigmoide se utiliza para filtrar los datos que son 0 o 1. Además, la función tanh limita el rango de enteros positivos al rango de 0 a 1. La función tanh clasifica la relevancia de los valores de entrada de −1 a 1 dividiéndolos por la salida sigmoide. La siguiente Figura 2.6 muestra las series temporales de LSTM. O W h x b h o C t o t t o t t t ( [ , ] ) tanh( ) 1
2.6 REDES NEURONALES RECURRENTES (RRN)
Una de las principales dificultades es la susceptibilidad de esta estrategia al problema de la pendiente creciente y la desaparición. Si se producen numerosos derivados mayores o pequeños, la fase de entrenamiento se inflará o decaerá. Debido a esto, la red deja de tener en cuenta las entradas iniciales cuando se reciben otras nuevas, y esta sensibilidad disminuye con el tiempo. Además, este problema podría resolverse con LSTM. Este método mantiene un enlace estable a los bancos de memoria distribuidos. Los estados temporales de la red pueden almacenarse en una o más de las celdas de memoria que componen cada bloque de memoria. Además, cuenta con elementos de puerta que controlan el flujo de información. En redes extremadamente profundas, los enlaces restantes también pueden servir como columna vertebral. Como veremos más adelante, estas medidas mitigan significativamente los efectos del problema del gradiente evanescente. Es ampliamente aceptado que RNN no es eficiente como CNN. La siguiente Figura 2.7 muestra la arquitectura RNN repetida,
2.6.1 ¿Cómo funcionan las RNN?
De la misma manera, la salida de ese tiempo influye en el tiempo t+1. Cualquier longitud de datos de entrada puede ser aceptada por una RNN. Aunque se utilizan datos anteriores durante el cálculo, el tamaño total del modelo permanece constante independientemente de la cantidad de datos que se introduzcan en él.
2.7 PERCEPTRONES MULTICAPA (MLP)
Las MLP son redes neuronales de realimentación. Constan de múltiples capas de perceptrones, cada una de las cuales tiene una función de activación. Todos los MLP tienen una capa de salida y una capa de entrada totalmente conectadas. Podrían implementarse en programas de reconocimiento de voz, reconocimiento de imágenes y traducción automática, todos los cuales tendrían el mismo número de capas de entrada y salida, además de la posibilidad de tener muchos más niveles ocultos.
2.7.1 ¿Cómo funcionan las MLP? El perceptrón multicapa (MLP) entrega la información a la capa de entrada de la red. Con el fin de asegurar que la señal solo viaja en una dirección, un gráfico
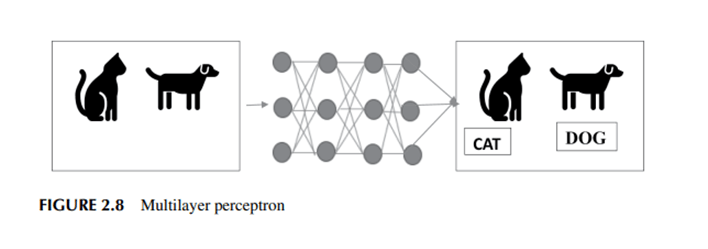
Representa las conexiones entre las diversas capas de neuronas. En los MLP, la entrada se calcula sopesando las conexiones entre las capas de entrada y la información oculta. En el caso de las MLP, la activación de un nodo está determinada por una función de activación. Funciones como el tanh, el sigmoid y el ReLu son ejemplos de funciones de activación. Mediante el empleo de un conjunto de datos de entrenamiento, los MLP educan el modelo para reconocer correlaciones y establecer dependencias entre las variables independientes y objetivo. En la figura 2.8 se realizan cálculos para determinar los pesos, el sesgo y las funciones de activación necesarias para asignar categorías a las imágenes de gatos y perros.

2.8 MAPAS AUTOORGANIZADOS (SOM)
2.8.1 ¿Cómo funcionan los SOM?
Los SOM eligen aleatoriamente un vector del conjunto de entrenamiento y asignan pesos a cada nodo. Para obtener los mejores pesos de vectores de entrada, los SOM investigan todos los nodos. La unidad que mejor coincide es el nodo victorioso (BMU). El número de vecinos eventualmente disminuye a medida que los SOM se vuelven más conscientes del entorno de la BMU. Los SOM favorecen el vector de muestra. Las transiciones de peso son más rápidas cerca de una BMU. Cuando un nodo está muy cerca de una BMU, se acelera la velocidad a la que cambia su peso. El vecino aprende menos cuanto más lejos está de la BMU. El SOM iterará sobre el paso dos un número infinito de veces. El diagrama codificado por colores de un vector de entrada se muestra en la Figura 2.9. Un SOM convierte esta información en valores RGB 2D. Por último, distingue los colores y los pone en orden.
2.9 REDES DE CREENCIAS PROFUNDAS (DBN)
2.9.1 ¿Cómo funcionan las DBN? Los algoritmos para el aprendizaje codicioso se utilizan para entrenar DBN. El enfoque de aprendizaje codicioso se utiliza para aprender los pesos generativos de arriba hacia abajo capa por capa. El muestreo de Gibbs se realiza en las dos capas ocultas superiores por DBN. En esta etapa se muestrea el RBM que han definido las dos capas ocultas superiores. DBN toma una muestra de las unidades que se pueden ver ejecutando una sola ejecución de muestreo ancestral sobre los componentes restantes del modelo, como se muestra en la Figura 2.10. Las DBN descubren que los valores se pueden deducir de un solo paso de abajo hacia arriba.
2.10 MÁQUINAS BOLTZMANN RESTRINGIDAS (RUL)
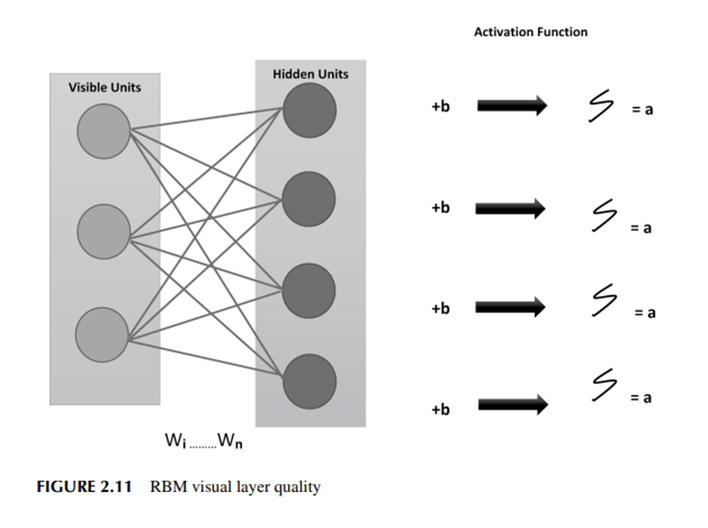
Los RBM se componen de dos capas: componentes visibles y unidades encubiertas. Cada unidad visible tiene conexiones a todas las unidades ocultas. Los nodos de salida están ausentes de los RBM, que en su lugar cuentan solo con una unidad de polarización vinculada a las unidades de entrada y salida.
2.10.1 ¿Cómo funcionan los mecanismos de encuadernación con anillos? En el paso hacia adelante, los RBM transforman las entradas en una serie de números enteros. Los pases hacia adelante y hacia atrás son fases de RBM. Los mecanismos de gestión basada en los resultados mezclan cada insumo con un único sesgo global y su propio peso. La salida del algoritmo se envía a la capa oculta. Los RBM utilizan ese conjunto de enteros para convertir las entradas reconstruidas en el paso inverso. Como se muestra en la Figura 2.11, los RBM suman los resultados de todas las activaciones y envían la señal combinada a la capa visual, donde puede ser reconstruida. La función evalúa la calidad de la capa visual comparando la imagen reconstruida con la entrada original.
2.11 AUTOCODIFICADORES
Un autocodificador de avance tiene la misma entrada y salida. Los autocodificadores fueron creados por Geoffrey Hinton en la década de 1980 para abordar problemas con el aprendizaje no supervisado [6]. La información introducida en estas redes neuronales entrenadas simplemente se recicla en la siguiente capa. Las aplicaciones de los codificadores automáticos incluyen el procesamiento de imágenes, la investigación de medicamentos y la predicción de popularidad.
2.10 MÁQUINAS BOLTZMANN RESTRINGIDAS (RUL)
Los RBM se componen de dos capas: componentes visibles y unidades encubiertas. Cada unidad visible tiene conexiones a todas las unidades ocultas. Los nodos de salida están ausentes de los RBM, que en su lugar cuentan solo con una unidad de polarización vinculada a las unidades de entrada y salida. 2.10.1 ¿Cómo funcionan los mecanismos de encuadernación con anillos? En el paso hacia adelante, los RBM transforman las entradas en una serie de números enteros. Los pases hacia adelante y hacia atrás son fases de RBM. Los mecanismos de gestión basada en los resultados mezclan cada insumo con un único sesgo global y su propio peso. La salida del algoritmo se envía a la capa oculta. Los RBM utilizan ese conjunto de enteros para convertir las entradas reconstruidas en el paso inverso. Como se muestra en la Figura 2.11, los RBM suman los resultados de todas las activaciones y envían la señal combinada a la capa visual, donde puede ser reconstruida. La función evalúa la calidad de la capa visual comparando la imagen reconstruida con la entrada original.

2.11.1 El propósito de los codificadores automáticos
El codificador, el código y el decodificador componen un codificador automático.
Los autocodificadores, como se muestra en la Figura 2.12, están construidos de tal manera que pueden tomar una sola entrada y generar una representación completamente nueva. Luego, intentan recrear fielmente la entrada original. Cuando la imagen de un dígito no es claramente visible, la información se envía a una red neuronal de autocodificador. Los cuidados curativos, preventivos, de rehabilitación y paliativos son proporcionados por diferentes partes de la industria médica o de la atención médica. Las empresas que se ocupan de la prevención, el diagnóstico, el tratamiento y la rehabilitación de enfermedades conforman la industria de la salud. La caridad puede darse de forma anónima o abierta y en forma de bienes o servicios [7]. Para satisfacer las necesidades de las personas y las comunidades en términos de atención médica, la industria de la salud moderna se divide en una amplia gama de subsectores, todos los cuales dependen de equipos interdisciplinarios compuestos por profesionales y paraprofesionales que han recibido capacitación.
2.12 IMPORTANCIA DE LAS INDUSTRIAS SANITARIAS
En todo el mundo, el sector de la salud es muy apreciado. Los fabricantes de equipos médicos, laboratorios de diagnóstico, hospitales, médicos, enfermeras, centros de vida asistida, farmacias y muchas más empresas conforman este sector de la economía [8]. Esta sección ofrece una visión general concisa del sector sanitario. La demanda de terapias médicas de estilo de vida y el crecimiento del negocio de la salud están influenciados principalmente por el envejecimiento de las poblaciones y la prevalencia de enfermedades crónicas. Los productos basados en tecnología médica tendrán una gran demanda durante bastante tiempo.
2.12.1 Aplicación del aprendizaje profundo en la atención médica
Las capacidades de aprendizaje profundo han mejorado significativamente la industria de la salud con la digitalización de datos y fotos médicas. Mediante la aplicación de software de reconocimiento de imágenes, los especialistas en imágenes y radiólogos pueden examinar y evaluar más imágenes en menos tiempo. El aprendizaje profundo está siendo utilizado por investigadores y profesionales de la salud para ayudar a descubrir e identificar el potencial sin explotar en los datos y mejorar el sector de la salud [9]. El aprendizaje profundo en la atención médica permite a los médicos evaluar adecuadamente cualquier enfermedad y respalda un mejor tratamiento de la enfermedad, lo que resulta en mejores decisiones médicas [3].
2.12.1.1 Investigación de medicamentos
El desarrollo de nuevos medicamentos se ve favorecido por el aprendizaje profundo en la profesión médica. El software analiza la historia clínica del paciente y sugiere el tratamiento más eficaz. Esta tecnología también recoge información de los resultados de las pruebas y los síntomas de los pacientes.
2.12.1.2 Diagnóstico por imágenes
Las enfermedades cardíacas, el cáncer y los tumores cerebrales son solo algunos ejemplos de condiciones médicas terribles que se pueden diagnosticar con la ayuda de procedimientos de imágenes médicas como resonancia magnética, tomografía computarizada y electrocardiograma.
FIGURA 2.12 Proceso del autocodificador 30 Aprendizaje profundo en el análisis de imágenes médicas
2.12.1.3 Robo de seguros
Las reclamaciones por fraude de seguros médicos se analizan con aprendizaje profundo. Las reclamaciones de fraude futuro podrían predecirse utilizando la ayuda de análisis predictivos. El aprendizaje profundo ayuda a la industria de seguros a llegar a sus clientes objetivo con descuentos y ofertas.
2.12.1.4 Enfermedad de Alzheimer
La enfermedad de Alzheimer es un problema importante al que se enfrenta el sector de las enfermedades médicas. Mediante el uso de algoritmos de aprendizaje profundo, la enfermedad de Alzheimer se diagnostica temprano.
2.12.1.5 Genoma
Los sistemas de aprendizaje profundo analizan un genoma para ayudar a los pacientes a identificar dolencias. La industria de los seguros y el campo de la genética tienen un futuro brillante para el aprendizaje profundo. Enlitic cree que el aprendizaje profundo mejora la precisión y la eficiencia de los profesionales médicos [10]. Con Cells Cope, los padres pueden controlar la salud de sus hijos en tiempo real a través de un teléfono inteligente inteligente, evitando la necesidad de visitas frecuentes al médico. Tanto el personal clínico como los pacientes pueden beneficiarse enormemente del uso del aprendizaje profundo en la atención sanitaria, lo que elevará el estándar del tratamiento.
2.13 APRENDIZAJE PROFUNDO EN EL PRONÓSTICO Y LA SUPERVIVENCIA DEL CÁNCER
La predicción del pronóstico es un componente crucial de la oncología clínica, ya que puede influir en las decisiones de tratamiento basadas en el curso esperado de la enfermedad y la probabilidad de supervivencia. El aprendizaje profundo tiene la capacidad de calcular el pronóstico y la tasa de supervivencia de los pacientes cuando se utiliza mediante datos genómicos, transcriptómicos y otras formas de datos [11]. El modelo de regresión de riesgo proporcional de Cox (Cox-PH) es el estándar de oro para predecir la supervivencia; Se trata de un modelo de regresión lineal multivariante que utiliza variables predictoras para establecer una relación entre el tiempo de supervivencia y las variables objeto de estudio. La estructura del PH lineal de Cox, cuando se aplica a datos genómicos y transcriptómicos, podría potencialmente ignorar las relaciones intrincadas y quizás no lineales entre los elementos. Las redes neuronales profundas, por otro lado, son inherentemente no lineales y podrían, en teoría, realizar esta tarea mejor que otras. Para el análisis de supervivencia de la DL, es interesante notar que varios estudios han utilizado la regresión de Cox. Estos modelos se entrenaron utilizando datos del transcriptoma para proporcionar mejores predicciones pronósticas. Cox-net fue una técnica innovadora que transformó el modelo de regresión de Cox en la capa de salida de la red neuronal utilizando como entrada los millones de características profundas obtenidas por las capas ocultas. Cox-net se entrenó utilizando datos de ARNuse de diez tipos de cáncer TCG A y fue el n en comparación con dos variantes de Cox-PH (Cox-PH y Cox Boost). Cox-net fue el único modelo capaz de diferenciar entre vías críticas como la señalización de p53, la endocitosis y las uniones adherentes. Su mayor precisión demostró que Cox-PH y las redes neuronales se pueden utilizar para recopilar datos biológicos relacionados con el pronóstico.
2.14 APRENDIZAJE PROFUNDO EN LA PREDICCIÓN DE ENFERMEDADES CARDÍACAS
Las afecciones cardíacas, a veces denominadas enfermedades cardiovasculares (ECV), han superado al cáncer como la enfermedad más peligrosa no solo en la India sino en todo el mundo en las últimas décadas. Una serie de trastornos relacionados con el calor pueden denominarse enfermedades cardíacas [12]. Muchos factores en su cuerpo podrían causar enfermedades cardíacas, lo que la convierte en una de las enfermedades más difíciles de predecir. La detección y el pronóstico de las enfermedades cardíacas son tareas desafiantes tanto para los médicos como para los investigadores. Por lo tanto, se necesita una técnica confiable, eficiente y útil para identificar estas enfermedades potencialmente mortales, así como la medicación necesaria.
2.15 ANÁLISIS Y DIAGNÓSTICO DE IMÁGENES
Las redes neuronales convolucionales (CNN) y otros enfoques de aprendizaje profundo son particularmente exitosos en el análisis de datos de rayos X y resonancias magnéticas. Según los expertos en ciencias de la computación de la Universidad de Stanford, las CNN se crean con la intención de procesar imágenes y aumentar la eficiencia de la red y el tamaño de la imagen. Como resultado, ciertas CNN se están volviendo más precisas en la identificación de rasgos clave en las investigaciones de diagnóstico por imágenes que los diagnosticadores humanos e incluso los están superando. Las redes neuronales convolucionales entrenadas para analizar imágenes dermatológicas identificaron correctamente el melanoma con un 10% más de precisión que los médicos humanos, según una investigación publicada en Annals of Oncology en junio de 2018. A pesar de la disponibilidad de historias clínicas humanas de los pacientes, CNN superó a los dermatólogos en casi un 7% en la ubicación corporal del rasgo problemático, incluida la edad, el sexo y el estado civil. El grupo de investigación de varias universidades alemanas concluyó que «nuestros datos implican claramente que un algoritmo CNN puede ser una herramienta adecuada para ayudar a los médicos en la detección del melanoma, independientemente de su grado específico de experiencia y formación». Las tecnologías de aprendizaje profundo son increíblemente precisas y rápidas. En la Escuela de Medicina Icahn de Mount Sinai, los investigadores han desarrollado una red neuronal profunda que es 150 veces más rápida que los radiólogos humanos para identificar trastornos neurológicos potencialmente mortales como el accidente cerebrovascular y la hemorragia cerebral. «Nuestros resultados demuestran que un método CNN puede ayudar a los médicos a diagnosticar el melanoma, independientemente de su nivel específico de experiencia y formación», escriben los investigadores. El software examinó la imagen, analizó los datos e informó un hallazgo clínico preocupante en 1,2 segundos. El Dr. Joshua Bederson, que dirige el departamento de neurología y es profesor de la universidad, afirma que «cualquier estrategia que minimice el tiempo de diagnóstico puede contribuir a mejorar los resultados de los pacientes, ya que la reacción temprana es fundamental en el tratamiento de las enfermedades neurológicas agudas». Dado lo bien que el aprendizaje profundo procesa las imágenes, algunos investigadores en este campo están creando imágenes médicas con redes neuronales. Los científicos de datos de la Clínica Mayo, NVIDIA y el Centro de Investigación Clínica de MGH y BWH, utilizando redes generativas adversarias (GAN), un tipo de aprendizaje profundo, pueden crear automáticamente imágenes médicas realistas.
2.16 HISTORIAS CLÍNICAS ELECTRÓNICAS (EHR)
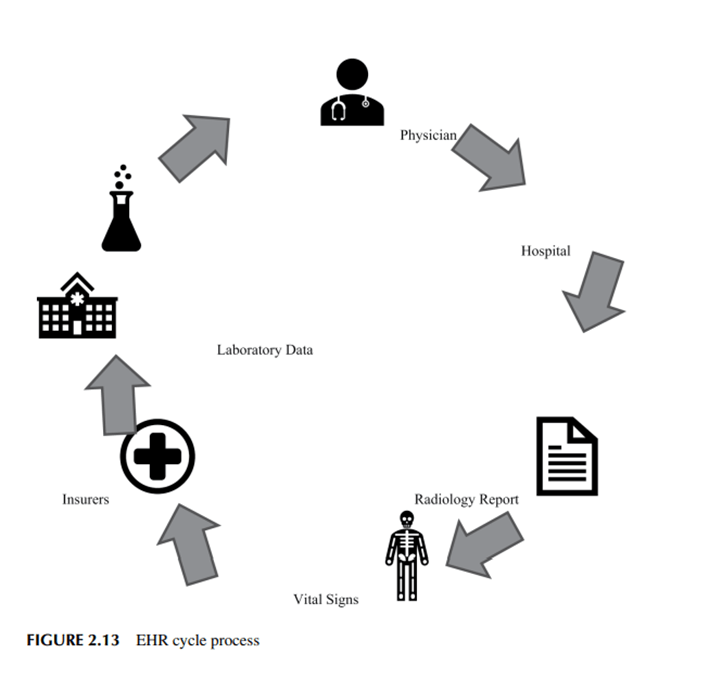
Las redes neuronales de aprendizaje profundo, como la memoria a corto plazo (LSTM), las unidades recurrentes generales (GRU), las redes neuronales recurrentes y las redes neuronales convolucionales unidimensionales, han demostrado ser de gran ayuda en el procesamiento del lenguaje natural. Estas redes son excelentes para manejar datos que están conectados a secuencias, como series temporales, oraciones y voz. La disciplina de la medicina computacional 32 Deep Learning in Medical Image Analysis utiliza tecnologías de procesamiento del lenguaje natural para procesar registros médicos electrónicos utilizando redes neuronales. El interés en el uso de EHR ha aumentado rápidamente en los últimos años. Una historia clínica electrónica contiene datos sobre la atención médica de los pacientes. Los datos incluyen lenguaje clínico no estructurado, información diagnóstica estructurada, información estructurada de prescripción, información estructurada sobre operaciones e información estructurada sobre resultados de pruebas experimentales [9]. La explotación de las historias clínicas electrónicas puede mejorar la medicina al mejorar la eficacia y la calidad de los diagnósticos [4]. Mediante el uso de los datos de las historias clínicas electrónicas para prever enfermedades, puede, por ejemplo, proporcionar a los pacientes un tratamiento oportuno. También puede ayudar a los médicos a tomar decisiones al observar las conexiones ocultas entre varias enfermedades, tratamientos y registros médicos electrónicos farmacéuticos. La Figura 2.13 muestra el proceso del ciclo de EHR. Dada la naturaleza secuencial de un EHR, las redes neuronales recurrentes como LSTM y GRU encuentran muchos usos en la industria médica. Al comparar las redes neuronales recurrentes con enfoques más convencionales, estos últimos fracasan estrepitosamente cuando se procesan registros médicos electrónicos.
La mayoría de los enfoques de aprendizaje profundo utilizados para recuperar datos de EHR son supervisados. Algunos investigadores analizan los datos electrónicos de salud mediante el aprendizaje no supervisado. La historia clínica electrónica se analiza mediante el uso de algoritmos de aprendizaje profundo para buscar patrones. El uso de los patrones aprendidos en tareas como la predicción de enfermedades, la predicción de eventos, la predicción de incidencia y otras es claramente el camino que tomarán las aplicaciones de aprendizaje profundo en el campo de los registros médicos electrónicos en un futuro próximo. La utilidad del aprendizaje profundo en las historias clínicas electrónicas ha sido demostrada por un número significativo de estudios. Sin embargo, se avecinan algunos desafíos para la futura implementación del aprendizaje profundo en las historias clínicas electrónicas: ¿Por qué es difícil analizar todos los tipos de datos incluidos en la historia clínica electrónica? [5]. La razón es que hay cinco formatos de datos distintos para las historias clínicas electrónicas: series temporales, como el historial del paciente; categorías, como la raza y el código internacional de enfermedades; objeto date-time, como la fecha de admisión del paciente; y numéricos, como el IMC. Además, los EHR son grandes, ruidosos, complejos y escasos. Los enfoques de aprendizaje profundo se enfrentan al reto de aplicar el modelo adecuado a los datos sanitarios electrónicos. El aprendizaje profundo en los EHR es lo suficientemente difícil como para que, en la práctica, la codificación del registro se altere debido a las diferencias en la oncología médica. El Código Nacional de Medicamentos, el Sistema Unificado de Lenguaje Médico y la ontología médica incluyen CIE-9, CIE-10 y códigos adicionales.
La implementación única conduce a datos no estándar, ya que varios departamentos u hospitales no siguen estrictamente las reglas de codificación de oncología médica. Las ontologías médicas pueden describir el mismo fenotipo de enfermedad. Por ejemplo, para el resultado de laboratorio de la hemoglobina A1C > 7.0, se puede utilizar el código 250.00 de la CIE-9 y el método de redacción de textos clínicos «diabetes mellitus tipo 2» para identificar a los pacientes en la historia clínica electrónica que han sido diagnosticados con «diabetes mellitus tipo 2». El procesamiento de datos es más difícil debido a los problemas antes mencionados. A los investigadores también les incomoda el mapeo entre los segundos.
2.16.1 Procesamiento del lenguaje natural (PNL)
Muchos sistemas de PNL utilizados en el cuidado de la salud para transcribir documentos y convertir audio a texto involucran aprendizaje profundo y redes neuronales. Las redes neuronales optimizadas para la categorización pueden descubrir características lingüísticas o gramaticales «agrupando» frases comparables. Para decirlo de otra manera, esto ayuda a la red a comprender significados semánticos más matizados. Sin embargo, el esfuerzo se complica por la complejidad del habla y el diálogo naturales [13]. Por ejemplo, el significado de un par de palabras que siempre se usan juntas en una expresión idiomática puede cambiar según el contexto, como se ve en frases como «patear el cubo» o «ladrar al árbol equivocado». La conversión de voz aceptable en texto ya es una práctica muy frecuente, y las tecnologías están ampliamente disponibles; Sin embargo, es mucho más difícil derivar conclusiones fiables y prácticas a partir de datos médicos de texto libre. Es de conocimiento común que las notas clínicas de texto libre en los registros electrónicos de salud (HCE) son torpes, incompletas, inconsistentes, llenas de acrónimos arcanos y están repletas de jerga. Por el contrario, las imágenes se componen de filas y columnas de píxeles especificadas. La tecnología superó a los métodos estándar en la detección de reingresos hospitalarios no planificados, la estimación de la duración de la estancia y la predicción de la mortalidad hospitalaria.
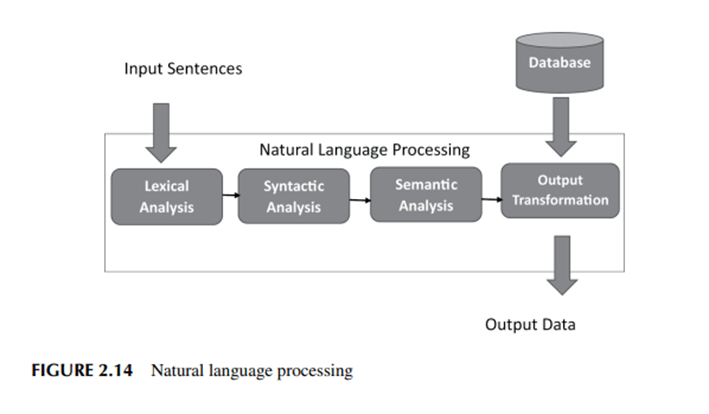
Al igual que las aplicaciones anteriores de EHR de aprendizaje profundo, los investigadores dijeron que esta predicción fue precisa y se alcanzó sin la selección manual de criterios evaluados para ser firmados por un experto. En cambio, nuestro programa tuvo en cuenta decenas de miles de variables, incluidas notas de texto libre, para determinar el pronóstico de cada paciente. Este es solo un estudio de prueba de concepto; Las búsquedas del investigador en Google creen que los resultados podrían tener consecuencias de gran alcance para las organizaciones de atención médica que buscan mejorar los resultados de los pacientes y ser más proactivas en la administración de la terapia necesaria. La siguiente Figura 2.14 muestra los conceptos de Procesamiento del Lenguaje Natural.
2.17 INFLUENCIA DEL DEEP LEARNING EN LA ATENCIÓN SANITARIA La atención sanitaria es una clara área de aplicación de la IA. Genera enormes cantidades de datos, gasta mucho dinero en ellos y tiene mucho espacio para mejorar la calidad de sus ofertas haciéndolas más intuitivas y sofisticadas. Pensar en la atención médica como una sola entidad es una tontería. Una de las tres ramas de la IA, fuera de los gigantes de la informática, que está haciendo los mayores avances es la automatización robótica de procesos (RPA). (Si bien no todos los RPA hacen uso de la IA [5], cada vez es más común). RPA sería una aplicación lógica porque los sistemas de salud en la mayoría de las naciones son procesos enormes y burocráticos. Smart dice que sería un desafío identificar varios problemas de salud [7].
2.17.1 Diagnóstico
Las dos aplicaciones de IA que ahora se están probando e implementando continuamente a escala, junto con RPA, son los chatbots y la analítica. Contrariamente a la creencia popular, los chatbots son menos comunes en la mayoría de los sistemas de atención médica, mientras que otras formas de análisis se están investigando ampliamente para el diagnóstico. Casi todos los días, un nuevo artículo informa que los robots han superado a los radiólogos o médicos humanos en el diagnóstico de algún mentor. FIGURA 2.14 Procesamiento del lenguaje natural: la influencia multifacética del aprendizaje profundo en los sistemas de atención médica 35
2.17.2 El cambio es difícil La industria de la salud lucha por ejecutar el cambio [10]. Hay muchos intereses poderosos y arraigados y, en ocasiones, no hay un mercado eficiente que fomente la innovación y promueva la eficiencia. La Administración de Alimentos y Medicamentos (FDA, por sus siglas en inglés) aprobó un sistema de anestesia robótica desarrollado por Johnson & Johnson para operaciones de rutina como colonoscopias en 2013 [14]. Se realizaron cientos de cirugías en Canadá y Estados Unidos con la ayuda de esta máquina a un costo de alrededor de $150 por cada procedimiento, en comparación con $2,000 con un anestesista humano. Sin embargo, la resistencia de la profesión llevó a una venta lenta.
2.17.3 La IA médica en las estrategias de consumo
En Polonia, otros piensan que la industria médica experimentará una transformación como resultado de los avances en la tecnología de consumo. Los Apple Watch ya pueden hacer un electrocardiograma, controlar la frecuencia cardíaca e identificar la fibrilación auricular. Nuestros niveles de glucosa en sangre se medirán mediante sensores simples y de bajo costo que se conectan a relojes, teléfonos celulares y, finalmente, anteojos inteligentes [15]. Se nos tomará la respiración y se examinará para buscar signos de cáncer o posibles problemas cardíacos. El cáncer de piel será detectado por las cámaras de nuestro teléfono, y la enfermedad de Parkinson será identificada por sus micrófonos, que captarán información sobre nuestro habla. Es posible que en diez años tengamos tantos sensores monitoreando constantemente nuestra salud como un vehículo de Fórmula Uno.
2.17.4 Democratización y descentralización
El brote de COVID-19 dejará una impresión duradera en la profesión médica. Will Smart estima que el 40% de las visitas médicas hoy en día involucran llamadas telefónicas o videollamadas. Sin duda, esto ahorra más tiempo al paciente que al médico, pero cuanto más dure la enfermedad, más difícil será volver a sus viejas rutinas [16]. El desarrollo es la telemedicina. Los chatbots se pueden utilizar en el triaje, por ejemplo, para decidir qué experto y con qué rapidez se debe atender la llamada de un paciente. Es posible que la medicina se vuelva democrática y descentralizada. La mayoría de los sistemas sanitarios modernos se centran en los hospitales de agudos. Se basan en un paradigma napoleónico creado para unir a los profesionales y mejorar la comunicación a un alto costo de capital. Sin embargo, es bien sabido que solo el 20% del bienestar total de un paciente es atribuible a la atención médica. El resto de los factores son los ingresos, el empleo, el estado civil y otros. En los últimos 200 años, los médicos se han especializado cada vez más; La IA puede permitirles volver a sus roles generalistas anteriores.
2.18 CONCLUSIÓN
Aunque los pilotos y los experimentos son emocionantes, su aplicación a la analítica sanitaria no ha hecho más que empezar. El aprendizaje profundo está cautivando a reguladores y legisladores, organizaciones comerciales, especialistas médicos e incluso personas. La Oficina del Coordinador Nacional de Tecnología de la Información de la Salud (ONC) de la Oficina de los 36 Deep Learning in Medical Image Analysis tiene grandes esperanzas en el futuro del aprendizaje profundo y ya ha honrado a algunos ingenieros destacados por sus contribuciones al campo. En un informe sobre la IA en la atención médica, la agencia dijo que los algoritmos de aprendizaje profundo han proporcionado resultados «transformadores». Los primeros éxitos en la clasificación del cáncer de piel y los exámenes de retina para diabéticos se mencionaron en el informe como dos aplicaciones del aprendizaje profundo. Debido a la ventaja inicial establecida en muchas aplicaciones de alto valor, se espera que el análisis de imágenes supere a otros campos de investigación clínica como el área dominante en un futuro próximo. Casi todos los principales proveedores de TI de salud priorizan «limpiar la basura», ya que la IA aprende el comportamiento del usuario, predice las necesidades y muestra hechos relevantes en el momento adecuado. Los clientes insatisfechos buscan mejores soluciones de estas empresas. Existe un consenso entre los pacientes y los profesionales de la salud de que la IA ha llegado a un punto en el que puede ayudar a facilitar soluciones e interacciones más centradas en el consumidor en el sector, con un número sorprendentemente grande de aplicaciones atractivas
