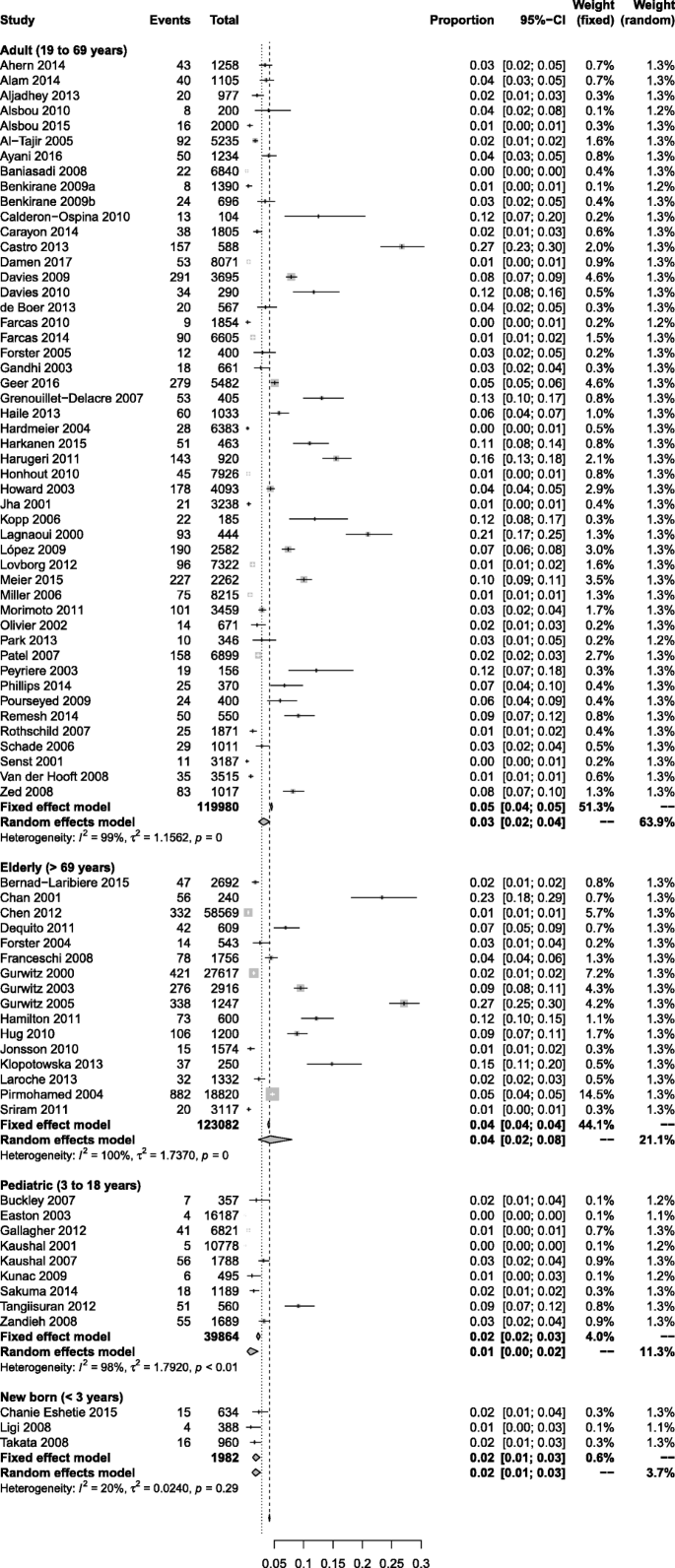
Cada industria fue una vez una industria en crecimiento. Pero algunos que ahora están montando una ola de entusiasmo por el crecimiento están muy a la sombra del declive. Otros, que se consideran industrias de crecimiento experimentado, en realidad han dejado de crecer. En todos los casos, la razón por la que el crecimiento se ve amenazado, ralentizado o detenido no es porque el mercado esté saturado. Es porque ha habido un fracaso de gestión.
PROPÓSITOS FALSOS
El fracaso en general está en la parte superior: Los ejecutivos responsables de ello, en última instancia, son aquellos que se ocupan de objetivos y políticas generales.
Así: Los ferrocarriles no dejaron de crecer porque la necesidad de transporte de pasajeros y carga disminuyó. Esto creció. Los ferrocarriles están en problemas hoy no porque la necesidad haya sido satisfecha por otros (automóviles, camiones, aviones, incluso teléfonos), sino porque no fue satisfecha por los propios ferrocarriles.
Dejaron que otros les quitaran clientes porque asumieron que estaban en el negocio ferroviario en lugar de en el negocio del transporte.
La razón por la que definieron mal su industria fue porque estaban orientados al ferrocarril en lugar de orientados al transporte; Estaban orientados al producto en lugar de orientados al cliente.
Hollywood:
Hollywood apenas escapó de ser totalmente destrozado por la televisión; En realidad, todas las compañías cinematográficas establecidas pasaron por reorganizaciones drásticas. Algunos simplemente desaparecieron. Todos ellos se metieron en problemas no por las incursiones de la televisión, sino por su propia miopía. Al igual que con los ferrocarriles, Hollywood definió su negocio incorrectamente. Pensó que estaba en el negocio del cine cuando en realidad estaba en el negocio del entretenimiento. «Películas» implicaba un producto específico y limitado. Esto produjo una satisfacción fatua, que desde el principio llevó a los productores a ver la televisión como una amenaza. Hollywood despreció y rechazó la televisión cuando debería haberla acogido como una oportunidad, una oportunidad para expandir el negocio del entretenimiento. Hoy en día, la televisión es un negocio más grande de lo que alguna vez fue el viejo negocio del cine.
Si Hollywood hubiera estado orientado al cliente (proporcionando entretenimiento), en lugar de orientado al producto (haciendo películas), ¿habría pasado por el purgatorio fiscal que hizo? Lo dudo. Lo que finalmente salvó a Hollywood y explicó su reciente resurgimiento fue la ola de nuevos escritores, productores y directores jóvenes cuyos éxitos anteriores en la televisión habían diezmado a las viejas compañías cinematográficas y derrocado a los grandes magnates del cine. Hay otros ejemplos menos obvios de industrias que han estado y están poniendo en peligro su futuro al definir incorrectamente sus propósitos. Discutiré algunos en detalle más adelante y analizaré el tipo de políticas que conducen a estos problemas. En este momento puede ayudar a mostrar lo que una gestión completamente orientada al cliente puede hacer para mantener una industria en crecimiento en crecimiento, incluso después de que se hayan agotado las oportunidades obvias;
Nylon y el vidrio:
Y aquí hay dos ejemplos que han existido durante mucho tiempo. Son nylon y vidrio, específicamente, E. I. DuPont de Nemours 8c Company y Corning Glass Works: Ambas compañías tienen una gran competencia técnica. Su orientación al producto es incuestionable. Pero esto por sí solo no explica su éxito.
Después de todo, ¿quién estaba más orgulloso de los productos y de los productos que las antiguas compañías textiles de Nueva Inglaterra que han sido tan completamente masacradas? DuPont y Corning han tenido éxito no principalmente debido a su orientación al producto o a la investigación, sino porque también han estado completamente orientados al cliente.
Es una vigilancia constante de las oportunidades para aplicar sus conocimientos técnicos a la creación de usos satisfactorios para el cliente, lo que explica su prodigiosa producción de nuevos productos exitosos. Sin un ojo muy sofisticado en el cliente, la mayoría de sus nuevos productos podrían haber estado equivocados, sus métodos de venta inútiles.
Aluminio:
El aluminio también ha seguido siendo una industria en crecimiento, gracias a los esfuerzos de dos compañías creadas en tiempos de guerra, que deliberadamente se dedicaron a crear nuevos usos satisfactorios para los clientes. Sin Kaiser Aluminum 8C Chemical Corporation y Reynolds Metals Company, la demanda total de aluminio hoy en día sería mucho menor de lo que es. Error de análisis Algunos pueden argumentar que es una tontería poner los ferrocarriles contra el aluminio o las películas contra el vidrio.
¿No son el aluminio y el vidrio naturalmente tan versátiles que las industrias están obligadas a tener más oportunidades de crecimiento que los ferrocarriles y las películas? Este punto de vista comete precisamente el error del que he estado hablando. Define una industria, o un producto, o un conjunto de conocimientos técnicos de manera tan estrecha como para garantizar su senescencia prematura.
Ferrocarriles
Cuando mencionamos «ferrocarriles», debemos asegurarnos de que queremos decir «transporte». Como transportistas, los ferrocarriles todavía tienen una buena oportunidad de un crecimiento muy considerable. No se limitan al negocio ferroviario como tal (aunque en mi opinión el transporte ferroviario es potencialmente un medio de transporte mucho más fuerte de lo que generalmente se cree).
Lo que les falta a los ferrocarriles no es oportunidad, sino algo de la misma imaginación y audacia gerencial que los hizo grandes. Incluso un aficionado como Jacques Barzun puede ver lo que falta cuando dice: Me duele ver que la organización física y social más avanzada del siglo pasado cae en desgracia por falta de la misma imaginación integral que la construyó. [Lo que falta es] la voluntad de las empresas de sobrevivir y satisfacer al público con inventiva y habilidad».
Es imposible mencionar una sola industria importante que en algún momento no calificó para la denominación mágica de «industria en crecimiento». En cada caso, su fuerza asumida radicaba en la superioridad aparentemente indiscutible de su producto. No parecía haber un sustituto eficaz para ello. Era en sí mismo un sustituto desbocado del producto que tan triunfalmente reemplazó. Sin embargo, una tras otra, estas célebres industrias han caído bajo la sombra.
Veamos brevemente algunos más de ellos, esta vez tomando ejemplos que hasta ahora han recibido un poco menos de atención: Jacques Barzun, «Trains and the Mind of Man», Holiday (febrero de 1960), p. 21
Limpieza en seco.
Esta fue una vez una industria en crecimiento con perspectivas lujosas. En una era de prendas de lana, imagina finalmente poder limpiarlas de manera segura y fácil. El boom estaba encendido. Sin embargo, aquí estamos 30 años después de que comenzara el auge y la industria está en problemas. ¿De dónde viene la competencia? ¿De una mejor forma de limpiar? No. Ha venido de fibras sintéticas y aditivos químicos que han reducido la necesidad de limpieza en seco. Pero esto es solo el comienzo. Al acecho en las alas y listo para hacer que la limpieza química en seco sea totalmente obsoleta está ese poderoso mago, ultrasónico. Servicios eléctricos. Este es otro de esos productos supuestamente «no sustitutos» que ha sido entronizado en un pedestal de crecimiento invencible. Cuando apareció la lámpara incandescente, se terminaron las luces de queroseno.
Más tarde, la rueda hidráulica y la máquina de vapor se cortaron en cintas por la flexibilidad, confiabilidad, simplicidad y simple disponibilidad de los motores eléctricos. La prosperidad de las empresas eléctricas continúa siendo extravagante a medida que la casa se convierte en un museo de aparatos eléctricos. ¿Cómo puede alguien fallar invirtiendo en servicios públicos, sin competencia, nada más que crecimiento por delante? Pero una segunda mirada no es tan reconfortante. Una veintena de compañías de servicios públicos no están muy avanzadas, desarrollando una poderosa celda de combustible químico que podría sentarse en algún armario oculto de cada hogar marcando silenciosamente la energía eléctrica. Las líneas eléctricas que vulgarizan tantos barrios serán eliminadas. También lo hará la demolición interminable de calles y las interrupciones del servicio durante las tormentas. También en el horizonte está la energía solar, nuevamente iniciada por compañías de servicios públicos.
¿Quién dice que las empresas de servicios públicos no tienen competencia?
Pueden ser monopolios naturales ahora, pero mañana pueden ser muertes naturales. Para evitar esta perspectiva, ellos también tendrán que desarrollar celdas de combustible, energía solar y otras fuentes de energía. Para sobrevivir, ellos mismos tendrán que tramar la obsolescencia de lo que ahora produce su sustento.
Supermercados.
A muchas personas les resulta difícil darse cuenta de que alguna vez hubo un establecimiento próspero conocido como la «tienda de comestibles de la esquina». El supermercado ha tomado el relevo con una poderosa efectividad. Sin embargo, las grandes cadenas de alimentos de la década de 1930 escaparon por poco de ser completamente aniquiladas por la agresiva expansión de los supermercados independientes.
El primer supermercado genuino se abrió en 1930, en Jamaica, Long Island. Para 1933, los supermercados prosperaban en California, Ohio, Pensilvania y otros lugares.
Sin embargo, las cadenas establecidas los ignoraron pomposamente. Cuando eligieron notarlos, fue con descripciones tan burlonas como cheapy», «caballo y buggy», «mantenimiento de tiendas de barriles de galletas» y «oportunidades poco éticas». El ejecutivo de una gran cadena anunció en ese momento que le resultaba «difícil creer que la gente conduzca por millas para comprar alimentos y sacrificar las cadenas de servicios personales que han perfeccionado y a las que la señora Consumer está acostumbrada». 2
Todavía en 1936, la Convención Nacional de Tiendas de Comestibles al por Mayor y la Asociación de Tiendas de Comestibles Minoristas de Nueva Jersey dijeron que no había nada que temer. Dijeron que el estrecho atractivo de los supers para el comprador de precios limitaba el tamaño de su mercado. Tenían que dibujar desde kilómetros a la redonda. Cuando llegaban los imitadores, había liquidaciones al por mayor a medida que el volumen caía. Se dijo que las altas ventas actuales de los supers se debían en parte a su novedad. Básicamente, la gente quiere tiendas de comestibles convenientes en el vecindario. Si las tiendas del vecindario «cooperan con sus proveedores, prestan atención a sus costos y mejoran sus servicios», podrían capear la competencia hasta que se desvanezca. 2Para más detalles, véase M. A Zimmerman, The Super Market: A Revolution in Distribution (Nueva York: McGraw-Hill Book Company, Inc., 1955), pág. 48. Nunca explotó. Las cadenas descubrieron que la supervivencia requería entrar en el negocio de los supermercados. Esto significó la destrucción total de sus enormes inversiones en tiendas de la esquina y en métodos establecidos de distribución y comercialización. Las empresas con «el coraje de sus convicciones» se apegaron resueltamente a la filosofía de la tienda de la esquina. Mantuvieron su orgullo pero perdieron sus camisas.
Ciclo de autoengaño
Pero los recuerdos son cortos. Por ejemplo, es difícil para las personas que hoy en día saludan con confianza a los mesías gemelos de la electrónica y los productos químicos ver cómo las cosas podrían salir mal con estas industrias galopantes.
Probablemente tampoco puedan ver cómo un hombre de negocios razonablemente sensato podría haber sido tan miope como el famoso millonario de Boston que hace 50 años sentenció involuntariamente a sus herederos a la pobreza al estipular que todo su patrimonio se invirtiera para siempre exclusivamente en valores de tranvías eléctricos. Su declaración póstuma, «Siempre habrá una gran demanda de transporte urbano eficiente», no es un consuelo para sus herederos que sostienen la vida bombeando gasolina en las estaciones de servicio de automóviles. Sin embargo, en una encuesta casual que hice recientemente entre un grupo de ejecutivos de negocios inteligentes, casi la mitad estuvo de acuerdo en que sería difícil dañar a sus herederos atando sus propiedades para siempre a la industria electrónica.
Cuando luego los confronté con el ejemplo del tranvía de Boston, corearon unánimemente: «¡Eso es diferente!» Pero, ¿lo es? ¿No es idéntica la situación básica? En verdad, no existe tal cosa como una industria en crecimiento, creo.
Solo hay empresas organizadas y operadas para crear y capitalizar oportunidades de crecimiento.
Las industrias que asumen que están montando una escalera mecánica de crecimiento automático invariablemente descienden al estancamiento.
La historia de cada industria de «crecimiento» muerta y moribunda muestra un ciclo autoengaños de expansión abundante y decadencia no detectada.
Hay cuatro condiciones, que generalmente garantizan este ciclo de autoengaño:
1. La creencia de que el crecimiento está asegurado por una población en expansión y más rica.
2. La creencia de que no hay sustituto competitivo para el principal producto de la industria.
3. Demasiada fe en la producción en masa y en las ventajas de disminuir rápidamente los costos unitarios a medida que aumenta la producción.
4. Preocupación por un producto que se presta a la experimentación científica cuidadosamente controlada, la mejora y la reducción de costos de fabricación.
Ahora me gustaría comenzar a examinar cada una de estas condiciones con cierto detalle.
Para construir mi caso lo más audazmente posible, ilustraré los puntos con referencia a tres industrias: petróleo, automóviles y electrónica, particularmente petróleo, porque abarca más años y más vicisitudes.
Estos tres no solo tienen una excelente reputación con el público en general y también disfrutan de la confianza de inversores sofisticados, sino que sus gerencias se han hecho conocidas por su pensamiento progresivo en áreas como el control financiero, la investigación de productos y la capacitación en administración.
Si la obsolescencia puede paralizar incluso estas industrias, puede suceder en cualquier lugar.
La creencia de que las ganancias están aseguradas por una población en expansión y más rica es querida por el corazón de cada industria. Quita el borde de las aprensiones que todos sienten comprensiblemente sobre el futuro. Si los consumidores se multiplican y además compran más de tu producto o servicio, puedes afrontar el futuro con mucha más comodidad que si el mercado se está reduciendo. Un mercado en expansión evita que el fabricante tenga que pensar mucho o imaginativamente. Si el pensamiento es una respuesta intelectual a un problema, entonces la ausencia de un problema conduce a la ausencia de pensamiento.
Si su producto tiene un mercado en expansión automática, entonces no pensará mucho en cómo expandirlo. Uno de los ejemplos más interesantes de esto es proporcionado por la industria petrolera.
Probablemente nuestra industria de crecimiento más antigua, tiene un historial envidiable.
Si bien hay algunas aprensiones actuales sobre su tasa de crecimiento, la industria en sí tiende a ser optimista. Pero creo que se puede demostrar que está experimentando un cambio fundamental pero típico.
No solo está dejando de ser una industria en crecimiento, sino que en realidad puede ser una en declive, en relación con otros negocios.
Aunque existe un desconocimiento generalizado de ello, creo que dentro de 25 años la industria petrolera puede encontrarse en la misma posición de gloria retrospectiva en la que se encuentran ahora las carreteras ferroviarias.
A pesar de su trabajo pionero en el desarrollo y la aplicación del método de evaluación de inversiones de valor presente, en las relaciones con los empleados y en el trabajo con países atrasados, el negocio del petróleo es un ejemplo angustiante de cómo la complacencia y la equivocación pueden convertir obstinadamente la oportunidad en casi un desastre.
Una de las características de esta y otras industrias que han creído firmemente en las consecuencias beneficiosas de una población en expansión, mientras que al mismo tiempo son industrias con un producto genérico para el que no parece haber un sustituto competitivo, es que las empresas individuales han tratado de superar a sus competidores mejorando lo que ya están haciendo.
Esto tiene sentido, por supuesto, si uno asume que las ventas están vinculadas a las cadenas de población del país, porque el cliente puede comparar productos solo característica por característica.
Creo que es significativo, por ejemplo, que desde que John D. Rockefeller envió lámparas de queroseno gratuitas a China la industria petrolera no haya hecho nada realmente sobresaliente para crear una demanda de su producto. Ni siquiera en la mejora del producto se ha bañado de eminencia. La mayor mejora, a saber, el desarrollo del tetraetilo de plomo, provino de fuera de la industria, específicamente de General Motors y DuPont.
Las grandes contribuciones hechas por la propia industria se limitan a la tecnología de exploración, producción y refinación de petróleo. En otras palabras, los esfuerzos de la industria se han centrado en mejorar la eficiencia de obtener y fabricar su producto, no realmente en mejorar el producto genérico o su comercialización. Además, su principal producto se ha definido continuamente en los términos más estrechos posibles, a saber, gasolina, no energía, combustible o transporte.
Esta actitud ha ayudado a asegurar que: Las mejoras importantes en la calidad de la gasolina tienden a no originarse en la industria petrolera. Además, el desarrollo de combustibles alternativos superiores proviene de fuera de la industria petrolera, como se mostrará más adelante. Las principales innovaciones en la comercialización de combustible para automóviles son originadas por pequeñas compañías petroleras nuevas que no se preocupan principalmente por la producción o refinación.
Estas son las compañías que han sido responsables de la rápida expansión de las estaciones de gasolina multibomba, con su énfasis exitoso en diseños grandes y limpios, servicio de entrada rápido y eficiente y gasolina de calidad a precios bajos. Por lo tanto, la industria petrolera está pidiendo problemas a los forasteros. Tarde o temprano, en esta tierra de inventores y empresarios hambrientos, seguramente vendrá una amenaza. Las posibilidades de esto se harán más evidentes cuando recurramos a la próxima creencia peligrosa de mucha gestión.
En aras de la continuidad, debido a que esta segunda creencia está estrechamente ligada a la primera, continuaré con el mismo ejemplo. La industria petrolera está bastante convencida de que no hay sustituto competitivo para su principal producto, la gasolina, o si lo hay, que seguirá siendo un derivado del petróleo crudo, como el combustible diesel o el combustible de queroseno para aviones. Hay muchas ilusiones automáticas en esta suposición.
El problema es que la mayoría de las compañías de refinación poseen enormes cantidades de reservas de petróleo crudo. Estos tienen valor solo si existe un mercado para productos en los que se puede convertir el petróleo, de ahí la creencia tenaz en la continua superioridad competitiva de los combustibles para automóviles hechos de petróleo crudo. Esta idea persiste a pesar de toda la evidencia histórica en su contra.
La evidencia no solo muestra que el petróleo nunca ha sido un producto superior para ningún propósito durante mucho tiempo, sino que también muestra que la industria petrolera nunca ha sido realmente una industria en crecimiento. Ha sido una sucesión de negocios diferentes que han pasado por los ciclos históricos habituales de crecimiento, madurez y decadencia. Su supervivencia global se debe a una serie de escapes milagrosos de la obsolescencia total, de indultos de última hora e inesperados del desastre total que recuerdan a los Peligros de Paulina. Peligros del petróleo Voy a esbozar sólo en los episodios principales: Primero, el petróleo crudo era en gran medida una medicina patentada. Pero incluso antes de que se agotara esa moda, la demanda se expandió enormemente por el uso de aceite en lámparas de queroseno. La perspectiva de encender las lámparas del mundo dio lugar a una extravagante promesa de crecimiento. Las perspectivas eran similares a las que la industria ahora tiene para la gasolina en otras partes del mundo. No puede esperar a que las naciones subdesarrolladas obtengan un automóvil en cada garaje.
En los días de la lámpara de queroseno, las compañías petroleras competían entre sí y contra la luz de gas al tratar de mejorar las características de iluminación del queroseno. Entonces, de repente, sucedió lo imposible. Edison inventó una luz que era totalmente no dependiente del petróleo crudo. Si no hubiera sido por el creciente uso de queroseno en los calentadores de espacio, la lámpara incandescente habría terminado completamente el aceite como una industria en crecimiento en ese momento. El aceite habría sido bueno para poco más que la grasa del eje. Entonces el desastre y el indulto golpearon de nuevo. Se produjeron dos grandes innovaciones, ninguna originada en la industria petrolera. El desarrollo exitoso de los sistemas de calefacción central doméstica que queman carbón hizo que el calentador de espacio quedara obsoleto. Mientras la industria se tambaleaba, llegó su impulso más magnífico hasta el momento: el motor de combustión interna, también inventado por extraños. Luego, cuando la prodigiosa expansión de la gasolina finalmente comenzó a estabilizarse en la década de 1920, llegó el escape milagroso de un calentador de aceite central. Una vez más, el escape fue proporcionado por la invención y el desarrollo de un extraño. Y cuando ese mercado se debilitó, la demanda de combustible de aviación en tiempos de guerra vino al rescate. Después de la guerra, la expansión de la aviación civil, la dieselización de los ferrocarriles y la demanda explosiva de automóviles y camiones mantuvieron el crecimiento de la industria en marcha.
Mientras tanto, la calefacción centralizada de petróleo, cuyo potencial de auge se había proclamado recientemente, se topó con una severa competencia del gas natural. Si bien las propias compañías petroleras poseían el gas que ahora competía con su petróleo, la industria no originó la revolución del gas natural, ni hasta el día de hoy se ha beneficiado enormemente de su propiedad de gas. La revolución del gas fue hecha por compañías de transmisión recién formadas que comercializaron el producto con un ardor agresivo.
Comenzaron una nueva industria magnífica, primero contra el consejo y luego contra la resistencia de las compañías petroleras. Según toda la lógica de la situación, las propias compañías petroleras deberían haber hecho la revolución del gas. No solo eran dueños del gas; También eran las únicas personas con experiencia en su manejo, fregado y uso, las únicas personas con experiencia en tecnología y transmisión de tuberías, y entendían los problemas de calentamiento. Pero, en parte porque sabían que el gas natural competiría con su propia venta de combustible para calefacción; Las compañías petroleras criticaron el potencial del gas. La revolución fue finalmente iniciada por ejecutivos de oleoductos que, incapaces de persuadir a sus propias compañías para que entraran en el gas, renunciaron y organizaron las compañías de transmisión de gas espectacularmente exitosas. Incluso después de que su éxito se hizo dolorosamente evidente para las compañías petroleras, estas últimas no entraron en la transmisión de gas. Los negocios multimillonarios de 9, que deberían haber sido suyos, fueron a otros. Como en el pasado, la industria estaba cegada por su estrecha preocupación por un producto específico y el valor de sus reservas. Prestó poca o ninguna atención a las necesidades y preferencias básicas de sus clientes. Los años de posguerra no han sido testigos de ningún cambio. Inmediatamente después de la Guerra Mundial Si la industria petrolera se sintió muy alentada sobre su futuro por la rápida expansión de la demanda de su línea tradicional de productos. En 1950, la mayoría de las empresas proyectaron tasas anuales de expansión interna de alrededor del 6% hasta al menos 1975. Aunque la relación entre las reservas de petróleo crudo y la demanda en el Mundo Libre era de aproximadamente 20 a 1, con 10 a I que generalmente se considera una relación de trabajo razonable en los Estados Unidos, la demanda en auge envió a los petroleros a buscar más sin tener en cuenta lo que el futuro realmente prometía. En 1952 «golpearon» en el Medio Oriente; La proporción se disparó a 42 a 1.
Si las adiciones brutas a las reservas continúan a la tasa promedio de los últimos cinco años (37 mil millones de barriles anuales), entonces para 1970 el coeficiente de reserva será de hasta 45 a 1. Esta abundancia de petróleo ha debilitado los precios del crudo y de los productos en todo el mundo. La gestión futura incierta no puede encontrar mucho consuelo hoy en la industria petroquímica en rápida expansión, otra idea de uso de petróleo que no se originó en las empresas líderes. La producción total de productos petroquímicos de los Estados Unidos equivale a aproximadamente el 2 por ciento (en volumen) de la demanda de todos los productos derivados del petróleo. Aunque ahora se espera que la industria petroquímica crezca alrededor del 10% anual, esto no compensará otros drenajes en el crecimiento del consumo de petróleo crudo. Además, si bien los productos petroquímicos son muchos y están creciendo, es bueno recordar que existen fuentes no petroleras de la materia prima básica, como el carbón. Además, se pueden producir muchos plásticos con relativamente poco aceite. Una refinería de petróleo de 50,000 barriles por día ahora se considera el tamaño mínimo absoluto para la eficiencia. Pero una planta química de 50.000 barriles por día es una operación gigante. El petróleo nunca ha sido una industria de crecimiento continuo y fuerte.
Ha crecido a trompicones, siempre milagrosamente salvado por innovaciones y desarrollos que no son de su propia creación. La razón por la que no ha crecido en una progresión suave es que cada vez que pensó que tenía un producto superior a salvo de la posibilidad de sustitutos competitivos, el producto resultó ser inferior y notoriamente sujeto a la obsolescencia. Hasta ahora, la gasolina (para combustible de motor, de todos modos) ha escapado a este destino. Pero, como veremos más adelante, también puede estar en sus últimas etapas. El punto de todo esto es que no hay garantía contra la obsolescencia del producto. Si la propia investigación de una empresa no la hace obsoleta, la de otra lo hará. A menos que una industria sea especialmente afortunada, como lo ha sido el petróleo hasta ahora, puede caer fácilmente en un mar de 10 cifras rojas tal como lo han hecho los ferrocarriles, como lo han hecho los fabricantes de látigos de buggy, como lo han hecho las cadenas de supermercados de la esquina, como la mayoría de las grandes compañías cinematográficas, y de hecho como muchas otras industrias tienen. La mejor manera de que una empresa tenga suerte es hacer su propia suerte. Eso requiere saber qué hace que un negocio sea exitoso. Uno de los mayores enemigos de este conocimiento es la producción en masa.
PRESIONES DE PRODUCCIÓN
Las industrias de producción en masa se ven impulsadas por un gran impulso para producir todo lo que puedan. La perspectiva de una fuerte disminución de los costos unitarios a medida que aumenta la producción es más de lo que la mayoría de las empresas generalmente pueden resistir. Las posibilidades de ganancias se ven espectaculares. Todo esfuerzo se centra en la producción. El resultado es que el marketing se descuida. John Kenneth Galbraith sostiene que ocurre justo lo contrario. La producción es tan prodigiosa que todo esfuerzo se concentra en tratar de deshacerse de ella. Él dice que esto explica el canto de comerciales, la profanación del campo con carteles publicitarios y otras prácticas derrochadoras y vulgares. Galbraith tiene un dedo en algo real, pero pierde el punto estratégico. La producción en masa genera una gran presión para mover» el producto. Pero lo que generalmente se enfatiza es la venta, no el marketing. El marketing, al ser un proceso más sofisticado y complejo, se ignora. La diferencia entre marketing y venta es más que semántica.
La venta se centra en las necesidades del vendedor, el marketing en las necesidades del comprador. La venta está preocupada por la necesidad del vendedor de convertir su producto en efectivo;
El Marketing se vincula con la idea de satisfacer las necesidades del cliente a través del producto y todo el conjunto de cosas asociadas con su creación, entrega y finalmente consumo.
En algunas industrias, los incentivos de la producción en masa completa han sido tan poderosos que durante muchos años la alta gerencia en efecto le ha dicho a los departamentos de ventas: Te deshaces de él; Nos preocuparemos por las ganancias».
Por el contrario, una empresa verdaderamente orientada al marketing trata de crear bienes y servicios que satisfagan el valor y que los consumidores quieran comprar. Lo que ofrece a la venta incluye no solo el producto o servicio genérico, sino también cómo se pone a disposición del cliente, en qué forma, cuándo, bajo qué condiciones y en qué términos de intercambio. Lo más importante es que lo que ofrece a la venta no está determinado por el vendedor sino por el comprador. El vendedor toma sus señales del comprador de tal manera que el producto se convierte en una consecuencia del esfuerzo de marketing, no al revés.
Retraso en Detroit
Esto puede sonar como una regla elemental de negocios, pero eso no evita que se viole al por mayor. Ciertamente es más violado que honrado. Tomemos la industria del automóvil: Aquí la producción en masa es la más famosa, la más honrada y tiene el mayor impacto en toda la sociedad.
La industria ha enganchado su fortuna a los implacables requisitos del cambio anual de modelo, una política que hace que la orientación al cliente sea una necesidad especialmente urgente.
En consecuencia, las compañías automotrices gastan anualmente millones de dólares en investigación de consumidores. Pero el hecho de que los nuevos autos compactos se vendan tan bien en su primer año indica que los vastos investigadores de Detroit no han revelado durante mucho tiempo lo que el cliente realmente quería. Detroit no estaba convencido de que quería algo diferente de lo que había estado obteniendo hasta que perdió millones de clientes a otros fabricantes de automóviles pequeños. I The Affluent Society (Boston: Hough ton-Mifflin Company, 1958), pp. 152-60.
¿Cómo podría este increíble retraso con respecto a los deseos de los consumidores haberse perpetuado durante tanto tiempo?
¿Por qué la investigación no reveló las preferencias de los consumidores antes de que las propias decisiones de compra de los consumidores revelaran los hechos?
¿No es para eso para lo que sirve la investigación del consumidor, para averiguar antes del hecho lo que va a suceder?
La respuesta es que Detroit nunca investigó realmente los deseos del cliente. Solo investigó sus preferencias entre el tipo de cosas, que ya había decidido ofrecerle. Porque Detroit está orientado principalmente al producto, no al cliente. En la medida en que se reconoce que el cliente tiene necesidades que el fabricante debe tratar de satisfacer, Detroit generalmente actúa como si el trabajo se pudiera hacer completamente mediante cambios de producto. De vez en cuando también se presta atención a la financiación, pero eso se hace más para vender que para permitir que el cliente compre. En cuanto a atender otras necesidades de los clientes, no se está haciendo lo suficiente para escribir. Las áreas de mayores necesidades insatisfechas son ignoradas, o en el mejor de los casos reciben atención del hijastro. Estos son en el punto de venta y en materia de reparación y mantenimiento de automóviles. Detroit considera que estas áreas problemáticas son de importancia secundaria. Esto se ve subrayado por el hecho de que los fines de venta al por menor y de servicio de esta industria no son propiedad ni están operados ni controlados por los fabricantes. Una vez que se produce el automóvil, las cosas están prácticamente en las manos inadecuadas del concesionario.
Ilustrativo de la actitud de distancia de Detroit es el hecho de que, si bien el servicio ofrece enormes oportunidades de generación de ganancias y estimulantes de ventas, solo 57 de los 7,000 concesionarios de Chevrolet brindan servicio de mantenimiento nocturno. Los automovilistas expresan repetidamente su insatisfacción con el servicio y sus aprensiones sobre la compra de automóviles bajo la configuración de venta actual. Las ansiedades y problemas que encuentran durante los procesos de compra y mantenimiento de automóviles son probablemente más intensos y generalizados hoy que hace 30 años. Sin embargo, las compañías automotrices no parecen escuchar o seguir el ejemplo del consumidor angustiado. Si escuchan, debe ser a través del filtro de su propia preocupación por la producción. El esfuerzo de marketing todavía se ve como una consecuencia necesaria del producto, no al revés, como debería ser. Ese es el legado de la producción en masa, con su visión parroquial de que el beneficio reside esencialmente en la producción completa de bajo costo. Lo que Ford puso primero El atractivo de ganancias de la producción en masa obviamente tiene un lugar en los planes y la estrategia de la gestión empresarial, pero siempre debe seguir un pensamiento cuidadoso sobre el cliente. Esta es una de las lecciones más importantes que podemos aprender del comportamiento contradictorio de Henry Ford. En cierto sentido, Ford fue el vendedor más brillante y sin sentido en la historia de Estados Unidos. No tenía sentido porque se negó a darle al cliente nada más que un automóvil negro. Fue brillante porque creó un sistema de producción diseñado para adaptarse a las necesidades del mercado. Habitualmente lo celebramos por la razón equivocada, su genio de producción. Su verdadero genio era el marketing. Creemos que pudo reducir su precio de venta y, por lo tanto, vender millones de autos de $ 500 porque su invención de la línea de ensamblaje había reducido los costos. En realidad, inventó la línea de montaje porque había llegado a la conclusión de que a 500 dólares podía vender millones de coches. La producción en masa fue el resultado, no la causa, de sus bajos precios.
Ford enfatizó repetidamente este punto, pero una nación de gerentes de negocios orientados a la producción se niega a escuchar la gran lección que enseñó. Aquí está su filosofía operativa como la expresó sucintamente: Nuestra política es reducir el precio, extender las operaciones y mejorar el artículo. Notarás que la reducción del precio es lo primero. Nunca hemos considerado ningún costo como fijo. Por lo tanto, primero reducimos el precio hasta el punto en que creemos que se producirán más ventas. Luego seguimos adelante y tratamos de hacer los precios. No nos preocupamos por los costos. El nuevo precio obliga a los costos a bajar. La forma más habitual es tomar los costos y luego determinar el precio; Y aunque ese método puede ser científico en el sentido estricto, no es científico en el sentido amplio, porque ¿de qué sirve saber el costo si te dice que no puedes fabricar a un precio al que se pueda vender el artículo? Pero más al punto es el hecho de que, aunque uno puede calcular lo que es un costo, y por supuesto todos nuestros costos se calculan cuidadosamente, nadie sabe cuál debería ser un costo. Una de las formas de descubrir… es nombrar un precio tan bajo como para obligar a todos en el lugar al punto más alto de eficiencia. El bajo precio hace que todos busquen ganancias. Hacemos más descubrimientos sobre la fabricación y venta bajo este método forzado que por cualquier método de investigación pausada.5 Provincialismo del producto Las tentadoras posibilidades de ganancias de los bajos costos unitarios de producción pueden ser la actitud más seriamente 13 autoengañosa que puede afligir a una empresa, particularmente a una empresa de «crecimiento» donde una expansión aparentemente asegurada de la demanda ya tiende a socavar una preocupación adecuada por la importancia del marketing y el cliente. El resultado habitual de esta estrecha preocupación por los llamados asuntos concretos es que en lugar de crecer, la industria declina. Por lo general, significa que el producto no se adapta a los patrones constantemente cambiantes de las necesidades y gustos de los consumidores, a las instituciones y prácticas de comercialización nuevas y modificadas, o a los desarrollos de productos en industrias competidoras o complementarias. La industria tiene sus ojos tan firmemente puestos en su propio producto específico que no ve cómo se está volviendo obsoleto. El ejemplo clásico de esto es la industria del látigo buggy. Ninguna cantidad de mejora del producto podría evitar su sentencia de muerte. Pero si la industria se hubiera definido a sí misma como en el negocio del transporte en lugar del negocio del látigo de buggy, podría haber sobrevivido. Habría hecho lo que la supervivencia siempre implica, es decir, cambiar. Incluso si solo hubiera definido su negocio como proporcionar un estimulante o catalizador a una fuente de energía, podría haber sobrevivido convirtiéndose en un fabricante de, por ejemplo, cintas de ventilador o purificadores de aire. Lo que algún día puede ser un ejemplo aún más clásico es, de nuevo, la industria petrolera. Habiendo dejado que otros le roben oportunidades maravillosas (por ejemplo, gas natural, como ya se mencionó, combustibles para misiles y lubricantes para motores a reacción), uno esperaría que hubiera tomado medidas para no permitir que eso volviera a suceder. Pero este no es el caso. Ahora estamos recibiendo nuevos desarrollos extraordinarios en sistemas de combustible diseñados específicamente para impulsar automóviles. Estos desarrollos no solo se concentran en empresas fuera de la industria petrolera, sino que el petróleo los ignora casi sistemáticamente, contento con su felicidad matrimonial con el petróleo. Es la historia del lam de queroseno contra la lámpara incandescente de nuevo. El petróleo está tratando de mejorar los combustibles de hidrocarburos en lugar de desarrollar los combustibles que mejor se adapten a las necesidades de sus usuarios, ya sea que se fabriquen o no de diferentes maneras y con diferentes materias primas del petróleo. Estas son algunas de las cosas en las que las compañías no petroleras están trabajando: · Más de una docena de estas empresas ahora tienen modelos avanzados de trabajo de sistemas de energía que, cuando se perfeccionen, reemplazarán el motor de combustión interna y eliminarán la demanda de gasolina. El mérito superior de cada uno de estos sistemas es su eliminación de paradas de reabastecimiento frecuentes, lentas e irritantes. La mayoría de estos sistemas son pilas de combustible diseñadas para crear energía eléctrica directamente a partir de productos químicos sin combustión. La mayoría de ellos utilizan productos químicos que no se derivan del petróleo, generalmente hidrógeno y oxígeno. 14 · Varias otras compañías tienen modelos avanzados de baterías de almacenamiento eléctrico diseñadas para alimentar automóviles. Uno de ellos es un productor de aviones que está trabajando conjuntamente con varias compañías eléctricas. Estos últimos esperan utilizar la capacidad de generación fuera de las horas pico para suministrar la regeneración de la batería enchufable durante la noche. Otra compañía, que también utiliza el enfoque de la batería, es una empresa de electrónica de tamaño mediano con una amplia experiencia en baterías pequeñas que desarrolló en relación con su trabajo en audífonos. Está colaborando con un fabricante de automóviles. 2Henry Ford, My Life and Work (Nueva York: Doubleday, Page & Company, 1923), pp. 146-47. Las recientes mejoras derivadas de la necesidad de plantas de almacenamiento de energía en miniatura de alta potencia en cohetes nos han puesto al alcance de una batería relativamente pequeña capaz de soportar grandes sobrecargas o sobretensiones de energía. Las aplicaciones de diodos de germanio y las baterías que utilizan técnicas de placa sinterizada y níquel-cadmio prometen hacer una revolución en nuestras fuentes de energía. · Los sistemas de conversión de energía solar también están recibiendo cada vez más atención.
Un ejecutivo automotriz de Detroit, generalmente cauteloso, recientemente aventuró que los autos que funcionan con energía solar podrían ser comunes para 1980.
En cuanto a las compañías petroleras, están más o menos «observando los acontecimientos», como me dijo un director de investigación.
Algunos están haciendo un poco de investigación sobre las pilas de combustible, pero casi siempre se limitan a desarrollar células alimentadas por productos químicos de hidrocarburos. Ninguno de ellos está investigando con entusiasmo las pilas de combustible, las baterías o las plantas de energía solar.
Ninguno de ellos está gastando una fracción tanto en investigación en estas áreas profundamente importantes como en las cosas habituales de la fábrica, como la reducción del depósito de la cámara de combustión en los motores de gasolina. Una importante compañía petrolera integrada recientemente echó un vistazo tentativo a la pila de combustible y concluyó que aunque «las compañías que trabajan activamente en ella indican una creencia en el éxito final… El momento y la magnitud de su impacto son demasiado remotos para justificar el reconocimiento en nuestros pronósticos». Uno podría, por supuesto, preguntarse:
¿Por qué las compañías petroleras deberían hacer algo diferente?
¿No matarían las pilas de combustible químicas, las baterías o la energía solar las líneas de productos actuales?
La respuesta es que sí, y esa es precisamente la razón por la que las empresas petroleras tienen que desarrollar estas unidades de potencia antes que sus competidores, por lo que no serán empresas sin industria.
Es más probable que la administración haga lo que se necesita para su propia preservación si se considera a sí misma como parte del negocio de la energía. Pero incluso eso no sería suficiente si persiste en aprisionarse en el estrecho agarre de su estrecha orientación al producto. Tiene que pensar en sí mismo como atender las necesidades del cliente, no encontrar, refinar o incluso vender petróleo. Una vez que realmente piensa en su negocio como el cuidado de las necesidades de transporte de las personas, nada puede impedirle crear su propio crecimiento extravagantemente rentable.
Destrucción creativa
Dado que las palabras son baratas y los hechos son caros, puede ser apropiado indicar lo que este tipo de pensamiento implica y conduce. Empecemos por el principio del cliente. Se puede demostrar que a los automovilistas no les gusta la molestia, el retraso y la experiencia de comprar gasolina. La gente en realidad no compra gasolina. No pueden verlo, saborearlo, sentirlo, apreciarlo o realmente probarlo. Lo que compran es el derecho a seguir conduciendo sus coches. La gasolinera es como un recaudador de impuestos al que la gente se ve obligada a pagar un peaje periódico como precio de usar sus automóviles. Esto hace que la gasolinera sea una institución básicamente impopular. Nunca puede hacerse popular o agradable, solo menos impopular, menos desagradable. Reducir su impopularidad por completo significa eliminarla. A nadie le gusta un recaudador de impuestos, ni siquiera uno agradablemente alegre. A nadie le gusta interrumpir un viaje para comprar un producto fantasma, ni siquiera de un apuesto Adonis o una seductora Venus. Por lo tanto, las empresas que están trabajando en sustitutos de combustibles exóticos, que eliminarán la necesidad de reabastecimiento frecuente, se dirigen directamente a los brazos extendidos de los automovilistas irritados. Están montando una ola de inevitabilidad, no porque estén creando algo, que es tecnológicamente superior o más sofisticado, sino porque están satisfaciendo una poderosa necesidad del cliente. También están eliminando los olores nocivos y la contaminación del aire. Una vez que las compañías petroleras reconozcan la lógica de satisfacción del cliente de lo que puede hacer otra potencia, verán que no tienen más opción de trabajar en un combustible eficiente y duradero (o alguna forma de entregar combustibles actuales sin molestar al automovilista) que las grandes cadenas de alimentos tenían la opción de entrar en el negocio de los supermercados. O las compañías de tubos de vacío tenían la opción de fabricar semiconductores. Por su propio bien, las empresas petroleras tendrán que destruir sus propios activos altamente rentables. Ninguna cantidad de ilusiones puede salvarlos de la necesidad de participar en esta forma de «destrucción creativa». Expreso la necesidad con tanta fuerza como esta porque creo que la administración debe hacer un gran esfuerzo para liberarse de las formas convencionales. Es demasiado fácil en esta época para una empresa o industria dejar que su sentido de propósito sea dominado por las economías de producción completa y desarrollar una orientación al producto peligrosamente desequilibrada.
En resumen, si la administración se deja desviar, invariablemente deriva en la dirección de pensar en sí misma como productora de bienes y servicios, no como satisfacción del cliente. Si bien probablemente no descenderá a las profundidades de decirle a sus vendedores: «Deshazte de él; Nos preocuparemos por las ganancias», puede, sin saberlo, estar practicando precisamente esa fórmula para la decadencia fulminante. El destino histórico de una industria en crecimiento tras otra ha sido su provincianismo producto suicida. Otro gran peligro para el crecimiento continuo de una empresa surge cuando la alta dirección está totalmente paralizada por las posibilidades de beneficios de la investigación y el desarrollo técnico. Para ilustrarlo, me referiré primero a una nueva industria: la electrónica y luego volveré una vez más a las compañías petroleras. Al comparar un nuevo ejemplo con uno familiar, espero enfatizar la prevalencia y la insidioso de una forma peligrosa de pensar.
En el caso de la electrónica, el mayor peligro al que se enfrentan las nuevas empresas glamurosas en este campo no es que no presten suficiente atención a la investigación y el desarrollo, sino que le presten demasiada atención. Y el hecho de que las empresas de electrónica de más rápido crecimiento deban su eminencia a su fuerte énfasis en la investigación técnica está completamente fuera de lugar. Han saltado a la riqueza en una cresta repentina de receptividad general inusualmente fuerte a las nuevas ideas técnicas.
Además, su éxito se ha configurado en el mercado virtualmente garantizado de subsidios militares y por órdenes militares que en muchos casos precedieron a la existencia de instalaciones para fabricar los productos. En otras palabras, su expansión ha estado casi totalmente desprovista de esfuerzo de marketing. Por lo tanto, están creciendo en condiciones que se acercan peligrosamente a crear la ilusión de que un producto superior se venderá solo. Habiendo creado una empresa exitosa haciendo un producto superior, no es sorprendente que la administración continúe orientada hacia el producto en lugar de las personas que lo consumen. Desarrolla la filosofía de que el crecimiento continuo es una cuestión de innovación y mejora continua del producto. Una serie de otros factores tienden a fortalecer y sostener esta creencia:
1. Debido a que los productos electrónicos son altamente complejos y sofisticados, las gerencias deben estar repletas de ingenieros y científicos. Esto crea un sesgo selectivo a favor de la investigación y la producción a expensas de la comercialización. La organización tiende a verse a sí misma como haciendo cosas en lugar de satisfacer las necesidades del cliente. El marketing se trata como una actividad residual, algo más» que debe hacerse una vez que se complete el trabajo vital de creación y producción de productos.
2. A este sesgo a favor de la investigación, el desarrollo y la producción de productos se agrega el sesgo a favor de tratar con variables controlables. Los ingenieros y científicos se sienten como en casa en el mundo de las cosas concretas como máquinas, tubos de ensayo, líneas de producción e incluso balances. Las abstracciones a las que se sienten amablemente son aquellas que son comprobables o manipulables en el laboratorio, o, si no son comprobables, entonces funcionales, como los axiomas de Euclides. En resumen, las gerencias de las nuevas compañías de crecimiento glamuroso tienden a favorecer aquellas actividades comerciales, que se prestan a un estudio cuidadoso, experimentación y control: las realidades duras y prácticas del laboratorio, la tienda y los libros. Lo que se queda corto son las realidades del mercado. Los consumidores son impredecibles, variados, volubles, estúpidos, miopes, tercos y, en general, molestos. Esto no es lo que dicen los ingenieros-gerentes, pero en el fondo de su conciencia es lo que creen. Y esto explica su concentración en lo que saben y lo que pueden controlar, es decir, la investigación de productos, la ingeniería y la producción. El énfasis en la producción se vuelve particularmente atractivo cuando el producto se puede hacer a costos unitarios decrecientes. No hay forma más atractiva de ganar dinero que haciendo funcionar la planta a toda máquina. Hoy en día, la orientación de producción, ingeniería e ingeniería de alto nivel de tantas compañías electrónicas funciona razonablemente bien porque están empujando hacia nuevas fronteras en las que las fuerzas armadas han sido pioneras en mercados prácticamente asegurados. Las empresas están en la feliz posición de tener que llenar, no encontrar, mercados; de no tener que descubrir lo que el cliente necesita y quiere, sino de hacer que el cliente presente voluntariamente nuevas demandas específicas de productos. Si se hubiera asignado específicamente un equipo de consultores para diseñar una situación comercial calculada para evitar la aparición y el desarrollo de un punto de vista de marketing orientado al cliente, no podría haber producido nada mejor que las condiciones que acabamos de describir. La industria petrolera es un ejemplo impresionante de cómo la ciencia, la tecnología y la producción en masa pueden desviar a todo un grupo de empresas de su tarea principal. En la medida en que se estudia al consumidor (que no es mucho), el enfoque siempre está en obtener información diseñada para ayudar a las compañías petroleras a mejorar lo que están haciendo ahora. Intentan descubrir temas publicitarios más convincentes, campañas promocionales de ventas más efectivas, cuáles son las cuotas de mercado de las diversas compañías, qué le gusta o no a la gente de los distribuidores de estaciones de servicio y las compañías petroleras, y así sucesivamente. Nadie parece tan interesado en investigar profundamente las necesidades humanas básicas que la industria podría estar tratando de satisfacer como en investigar las propiedades básicas de la materia prima con la que las empresas trabajan para tratar de satisfacer a los clientes. Las preguntas básicas sobre los clientes y los mercados rara vez se hacen. Estos últimos ocupan un estatus de hijastro. Se reconoce que existen, que deben ser atendidos, pero no merecen mucha reflexión real o atención dedicada. Nadie se entusiasma tanto con los clientes en su propio patio trasero como con el petróleo en el desierto del Sahara. Nada ilustra mejor el descuido del marketing que su tratamiento en la prensa de la industria: el número centenario del American Petroleum Institute Quarterly, publicado en 1959 para celebrar el descubrimiento de petróleo en Titusville, Pensilvania, contenía 21 artículos destacados que proclamaban la grandeza de la industria. Solo uno de ellos habló sobre sus logros en marketing, y eso fue solo un registro pictórico de cómo ha cambiado la arquitectura de las estaciones de servicio.
El número también contenía una sección especial sobre «Nuevos horizontes», que estaba dedicada a mostrar el magnífico papel que desempeñaría el petróleo en el futuro de Estados Unidos. Cada referencia era exuberantemente optimista, sin implicar ni una sola vez que el petróleo podría tener una dura competencia. Incluso la referencia a la energía atómica era un catálogo alegre de cómo el petróleo ayudaría a que la energía atómica fuera un éxito. No había una sola aprensión de que la riqueza de la industria petrolera pudiera verse amenazada o una sugerencia de que un «nuevo horizonte» podría incluir nuevas y mejores formas de servir a los clientes actuales del petróleo.
Pero el ejemplo más revelador del tratamiento de hijastro que recibe el marketing fue otra serie especial de artículos cortos sobre «El potencial revolucionario de la electrónica». Bajo ese título, esta lista de artículos apareció en la tabla de contenido: «En la búsqueda de petróleo» «En las operaciones de producción» «En los procesos de refinería» «En las operaciones de oleoductos» Significativamente, se enumeran todas las principales áreas funcionales de la industria, excepto el marketing. ¿Por qué? O se cree que la electrónica no tiene un potencial revolucionario para la comercialización del petróleo (lo cual es palpablemente erróneo), o los editores se olvidaron de discutir el marketing (que es más probable, e ilustra su estado de hijastro). El orden en que se enumeran las cuatro áreas funcionales también revela la alienación de la industria petrolera del consumidor. La industria se define implícitamente como comenzando con la búsqueda de petróleo y terminando con su distribución desde la refinería. Pero la verdad es, me parece, que la industria comienza con las necesidades del cliente para sus productos. Desde esa posición primordial, su definición se mueve constantemente hacia áreas de menor importancia, hasta que finalmente se detiene en la «búsqueda de petróleo». La visión de que una industria es un proceso que satisface al cliente, no un proceso de producción de bienes, es vital para que todos los empresarios lo entiendan. Una industria comienza con el cliente y sus necesidades, no con una patente, una materia prima o una habilidad de venta. Dadas las necesidades del cliente, la industria se desarrolla hacia atrás, primero preocupándose por la entrega física de las satisfacciones del cliente. Luego retrocede más hacia la creación de las cosas por las cuales estas satisfacciones se logran en parte. La forma en que se crean estos materiales es una cuestión de indiferencia para el cliente, por lo tanto, la forma particular de fabricación, procesamiento o lo que tiene no puede considerarse como un aspecto vital de la industria. Finalmente, la industria retrocede aún más para encontrar las materias primas necesarias para fabricar sus productos. La ironía de algunas industrias orientadas a la investigación y el desarrollo técnico es que los científicos que ocupan los altos cargos ejecutivos son totalmente acientíficos cuando se trata de definir las necesidades y propósitos generales de sus empresas. Violan las dos primeras reglas del método científico conociendo y definiendo los problemas de sus empresas, y luego desarrollando hipótesis comprobables sobre cómo resolverlos. Son científicos solo sobre las cosas convenientes, como experimentos de laboratorio y productos. La razón por la que el cliente (y la satisfacción de sus necesidades más profundas) no se considera como «el problema no es porque haya una cierta creencia de que no existe tal problema, sino porque una vida organizacional ha condicionado a la gerencia a mirar en la dirección opuesta. Es como si vivieran en una economía planificada, moviendo sus productos rutinariamente de la fábrica al punto de venta. Su concentración exitosa en productos tiende a convencerlos de la solidez de lo que han estado haciendo, y no logran ver las nubes que se ciernen sobre el mercado.
Hace menos de 75 años, los ferrocarriles estadounidenses disfrutaban de una lealtad feroz entre los astutos de Wall Street.
Los monarcas europeos invirtieron mucho en ellos.
Se pensaba que la riqueza eterna era la bendición para cualquiera que pudiera juntar unos pocos miles de dólares para ponerlos en acciones ferroviarias. Ninguna otra forma de transporte podría competir con los ferrocarriles en velocidad, flexibilidad, durabilidad, economía y potencial de crecimiento.
Como dijo Jacques Barzun: «Para el cambio de siglo era una institución, una imagen del hombre, una tradición, un código de honor, una fuente de poesía, una guardería de deseos de la infancia, un sublimes de juguetes y la máquina más solemne -junto al coche fúnebre funerario- que marca las épocas en la vida del hombre».
Incluso después del advenimiento de los automóviles, camiones y aviones, los magnates del ferrocarril permanecieron imperturbablemente seguros de sí mismos. Si les hubieras dicho hace 60 años que en 30 años estarían de espaldas, en bancarrota y suplicando subsidios del gobierno, habrían pensado que estás totalmente demente. Tal futuro simplemente no se consideraba posible. Ni siquiera era un tema discutible, o una pregunta que se pudiera hacer, o un asunto sobre el que cualquier persona sensata consideraría digno de especular. El solo pensamiento era una locura.
Sin embargo, muchas nociones locas ahora tienen aceptación práctica, por ejemplo, la idea de tubos de metal de 100 toneladas que se mueven suavemente por el aire a 20,000 pies sobre la tierra, cargados con 100 ciudadanos cuerdos y sólidos bebiendo casualmente martinis y han asestado golpes crueles a los ferrocarriles.
¿Qué deben hacer específicamente otras empresas para evitar este destino? ¿En qué consiste la orientación al cliente?
Estas preguntas han sido respondidas en parte por los ejemplos y análisis anteriores. Se necesitaría otro artículo para mostrar en detalle lo que se requiere para industrias específicas. En cualquier caso, debería ser obvio que construir una empresa eficaz orientada al cliente implica mucho más que buenas intenciones o trucos promocionales; Implica asuntos profundos de organización humana y liderazgo. Por el momento, permítanme simplemente sugerir lo que parecen ser algunos requisitos generales. Sensación visceral de grandeza Obviamente la empresa tiene que hacer lo que exige la supervivencia. Tiene que adaptarse a las exigencias del mercado, y tiene que hacerlo más pronto que tarde. Pero la mera supervivencia es una aspiración regular. Cualquiera puede sobrevivir de una manera u otra, incluso el vagabundo del skidrow. El truco es sobrevivir galantemente, sentir el impulso creciente del dominio comercial; No solo para experimentar el dulce olor del éxito, sino para tener la sensación visceral de la grandeza empresarial. Ninguna organización puede alcanzar la grandeza sin un líder vigoroso que sea impulsado hacia adelante por su propia voluntad palpitante de tener éxito. Tiene que tener una visión de grandeza, una visión que pueda producir seguidores ansiosos en grandes cantidades. En 21 negocios, los seguidores son los clientes. Para producir estos clientes, toda la corporación debe ser vista como un organismo creador de clientes y satisfaciendo al cliente. La administración debe pensar en sí misma no como la producción de productos, sino como la satisfacción de valor de creación de valor del cliente. Debe impulsar esta idea (y todo lo que significa y requiere) en cada rincón y grieta de la organización. 6Barzun, op. cit., pág. 20. Tiene que hacer esto continuamente y con el tipo de estilo que excita y estimula a las personas en él. De lo contrario, la empresa será simplemente una serie de piezas encasilladas, sin un sentido consolidado de propósito o dirección.
En resumen, la organización debe aprender a pensar en sí misma no como la producción de bienes o servicios, sino como la compra de clientes, como haciendo las cosas que harán que la gente quiera hacer negocios con ella. Y el propio director ejecutivo tiene la responsabilidad ineludible de crear este entorno, este punto de vista, esta actitud, esta aspiración. Él mismo debe establecer el estilo de la empresa, su dirección y sus objetivos. Esto significa que tiene que saber exactamente a dónde quiere ir, y asegurarse de que toda la organización sea consciente con entusiasmo de dónde está.
Este es un primer requisito del liderazgo, porque a menos que sepa a dónde va, cualquier camino lo llevará allí. Si algún camino está bien, el director ejecutivo también podría empacar su cuidado attach6 e ir a pescar. Si una organización no sabe o no le importa a dónde va, no necesita anunciar ese hecho con una figura ceremonial. Todo el mundo lo notará muy pronto.
1975: COMENTARIO RETROSPECTIVO
Asombrado, finalmente, por su éxito literario, Isaac Bashevis Singer reconcilió un problema concomitante: «Creo que en el momento en que has publicado un libro, ya no es tu propiedad privada. . . . Si tiene valor, todos pueden encontrar en él lo que encuentran, y no puedo decirle al hombre que no tenía la intención de que fuera así».
En los últimos 15 años, la «miopía de marketing» se ha convertido en un buen ejemplo. Sorprendentemente, el artículo generó una legión de partidarios leales, sin mencionar una gran cantidad de compañeros de cama poco probables. Su consecuencia más común y, creo, más influyente es la forma en que ciertas empresas por primera vez pensaron seriamente en la cuestión de en qué negocios se encuentran realmente. Las consecuencias estratégicas de esto han sido en muchos casos dramáticas. El caso más conocido, por supuesto, es el cambio de pensar en uno mismo como si estuviera en el «negocio del petróleo» a estar en el «negocio de la energía».
En algunos casos, la recompensa ha sido espectacular (entrar en el carbón, por ejemplo) y en otros terrible (en términos del tiempo y el dinero gastado hasta ahora en la investigación de celdas de combustible). Otro ejemplo exitoso es una empresa con una gran cadena de tiendas minoristas de calzado que la redefinió como un minorista de productos especializados de consumo moderadamente de precio, comprados con frecuencia y ampliamente variados. El resultado fue un crecimiento dramático en volumen, ganancias y rendimiento de los activos.
Algunas empresas, de nuevo por primera vez, se preguntaron si deseaban dominar ciertas tecnologías, para las que buscarían mercados, o ser dueñas de mercados para los que buscarían productos y servicios que satisfagan al cliente. Al elegir el primero, una compañía ha declarado, en efecto, «Somos expertos en tecnología de vidrio. Tenemos la intención de mejorar y ampliar esa experiencia con el objetivo de crear productos que atraigan a los clientes».
Esta decisión ha obligado a la compañía a una mirada mucho más sistemática y sensible al cliente sobre posibles mercados y usuarios, a pesar de que su objetivo estratégico declarado ha sido capitalizar la tecnología del vidrio. Al decidir concentrarse en los mercados, otra compañía ha determinado que «queremos ayudar a las personas (principalmente mujeres) a mejorar su belleza y sentido de plenitud juvenil». Esta compañía ha ampliado su línea de productos cosméticos, pero también ha entrado en los campos de medicamentos patentados y suplementos vitamínicos.
Todos estos ejemplos ilustran los resultados «políticos» de la «miopía de marketing».
A nivel operativo, ha habido, creo, un aumento extraordinario de la sensibilidad hacia los clientes y consumidores. Los departamentos de investigación y desarrollo han cultivado una mayor orientación «externa» hacia los usos, los usuarios y el equilibrio de mercados, por lo tanto, el enfoque «interno» previamente unilateral en materiales y métodos;
La alta dirección se ha dado cuenta de que los departamentos de marketing y ventas deberían acomodarse de manera algo más dispuesta que antes; los departamentos de finanzas se han vuelto más receptivos a la legitimidad de los presupuestos para la investigación de mercado y la experimentación en marketing; Y los vendedores han sido mejor entrenados para escuchar y comprender las necesidades y problemas de los clientes, en lugar de simplemente «empujar» el producto. Un espejo, no una ventana
Mi impresión es que el artículo ha tenido más impacto en las empresas de productos industriales que en las empresas de productos de consumo, tal vez porque las primeras se habían quedado más rezagadas en la orientación al cliente.
Hay al menos dos razones para este retraso:
(1) las empresas de productos industriales tienden a ser más intensivas en capital, y
(2) en el pasado, al menos, han tenido que depender en gran medida de comunicar cara a cara el carácter técnico de lo que fabrican y venden.
Vale la pena explicar estos puntos. Las empresas intensivas en capital están comprensiblemente preocupadas por las magnitudes, especialmente cuando el capital, una vez invertido, no puede ser fácilmente movido, manipulado o modificado para la producción de una variedad de productos, por ejemplo, plantas químicas, acerías, aerolíneas y ferrocarriles.
Comprensiblemente, buscan grandes volúmenes y eficiencias operativas para pagar el equipo y cumplir con los costos de transporte.
Al menos un problema resulta: el poder corporativo se aloja desproporcionadamente en los ejecutivos operativos o financieros. Si Usted leyó el estatuto de una de las compañías más grandes del país; Verán que el presidente del comité de finanzas, no el director ejecutivo, es el «jefe». Los ejecutivos con tales antecedentes tienen una incapacidad casi entrenada para ver que obtener volumen» puede requerir comprender y servir a muchos segmentos de mercado discretos y, a veces, pequeños, en lugar de perseguir a un grupo quizás mítico de clientes grandes u homogéneos.
Estos ejecutivos a menudo tampoco aprecian los cambios competitivos que ocurren a su alrededor. Observan los cambios, de acuerdo, pero devalúan su importancia o subestiman su capacidad para mordisquear los mercados de la compañía. Sin embargo, una vez alertados dramáticamente sobre el concepto de segmentos, sectores y clientes, los gerentes de negocios intensivos en capital se han vuelto más receptivos a la necesidad de equilibrar su preocupación ineludible con «pagar las facturas» o alcanzar el punto de equilibrio con el hecho de que la mejor manera de lograr esto puede ser prestar más atención a los segmentos, sectores y clientes.
La segunda razón por la que las empresas de productos industriales probablemente han sido más influenciadas por el artículo es que, en el caso de los productos o servicios industriales más técnicos, la necesidad de comunicar claramente las características de los productos y servicios a los prospectos resulta en un gran esfuerzo de «venta» cara a cara. Pero precisamente porque el producto es tan complejo, la situación produce vendedores que conocen el producto más de lo que conocen al cliente que son más expertos en explicar lo que tienen y lo que puede hacer que aprender cuáles son las necesidades y problemas del cliente.
El resultado ha sido una orientación estrecha al producto en lugar de una orientación liberadora al cliente, y el «servicio» a menudo sufrió. Sin duda, los vendedores dijeron: «Tenemos que proporcionar servicio», pero tendían a definir el servicio mirándose en el espejo en lugar de por la ventana. Pensaron que estaban mirando por la ventana al cliente, pero en realidad era un espejo, un reflejo de sus propios sesgos orientados al producto en lugar de un reflejo de las situaciones de sus clientes.
Un manifiesto, no una receta No todo ha sido color de rosa.
Muchas cosas extrañas han sucedido como resultado del artículo:
Algunas empresas han desarrollado lo que yo llamo «manía del marketing»: se han vuelto obsesivamente receptivas a cada capricho fugaz del cliente. Las operaciones de producción en masa se han convertido en aproximaciones de talleres de trabajo, con consecuencias de costo y precio que superan con creces la disposición de los clientes a comprar el producto.
· La administración ha ampliado las líneas de productos y ha agregado nuevas líneas de negocios sin establecer primero sistemas de control adecuados para ejecutar operaciones más complejas. ·
El personal de marketing se ha expandido repentina y rápidamente a sí mismo y a sus presupuestos de investigación sin obtener suficiente apoyo organizativo previo o, posteriormente, producir resultados suficientes. ·
Las empresas que están organizadas funcionalmente se han convertido en organizaciones basadas en productos, marcas o mercados con la expectativa de resultados instantáneos y milagrosos. El resultado ha sido ambigüedad, frustración, confusión, luchas internas corporativas, pérdidas y, finalmente, una reversión a arreglos funcionales que solo empeoraron la situación. ·
Las empresas han intentado «servir» a los clientes mediante la creación de productos o servicios complejos y bellamente eficientes que los compradores son demasiado reacios al riesgo para adoptar o incapaces de aprender a emplear el efecto, ahora hay palas de vapor para las personas que aún no han aprendido a usar palas. Este problema ha ocurrido repetidamente en las llamadas industrias de servicios (servicios financieros, seguros, servicios informáticos) y con empresas estadounidenses que venden en economías menos desarrolladas.
La «miopía del marketing» no pretendía ser un análisis o incluso una prescripción; Fue pensado como manifiesto. No pretendía adoptar una posición equilibrada.
Tampoco era una idea nueva: Peter F. Drucker, J. B. McKitterick, Wroe Alderson, John Howard y Neil Broden habían hecho un trabajo más original y equilibrado sobre «el concepto de marketing».
Mi esquema, sin embargo, vinculó el Marketing más estrechamente a la órbita interna de la política empresarial. Drucker, especialmente en The Concept of the Corporation y The Practice of Management, originalmente me proporcionó una gran cantidad de información. Mi contribución, por lo tanto, parece haber sido simplemente una forma simple, breve y útil de comunicarse y una forma existente de pensar.
Traté de hacerlo de una manera muy directa, pero responsable, sabiendo que pocos lectores (clientes), especialmente gerentes y líderes, podrían soportar muchos equívocos o dudas.
También sabía que la afirmación colorida y ligeramente documentada funciona mejor que la explicación tortuosamente razonada.
Pero, ¿por qué la enorme popularidad de lo que en realidad era una idea preexistente tan simple?
¿Por qué los llamamientos en todo el mundo a académicos resueltamente restringidos, gerentes implacablemente moderados y altos funcionarios gubernamentales, todos acostumbrados a cálculos equilibrados y reflexivos?
¿Es que ejemplos concretos, unidos para ilustrar una idea simple y presentados con cierta atención a la alfabetización, comunicando mejor que el razonamiento analítico masivo que se lee como si hubiera sido traducido del alemán?
¿Son las afirmaciones provocativas más memorables o persuasivas que las explicaciones moderadas y equilibradas, sin importar quién sea la audiencia?
¿Es que el personaje o el mensaje es tanto el mensaje como su contenido? ¿O no era simplemente una melodía diferente, sino una nueva sinfonía?
¿No sé?
Por supuesto, lo haría de nuevo y de la misma manera, dados mis propósitos, incluso con lo que más sé ahora: lo bueno y lo malo, el poder de los hechos y los límites de la retórica.
Si tu misión es la luna, no usas un automóvil.
La cucaracha de Don Marqués, Archy, proporciona un consuelo final: «una idea no es responsable de quién cree en ella».














 928
928 134
134 927
927 134
134 395
395 134
134 395
395 134
134 923
923 134
134 926
926 134
134 927
927 134
134 927
927 134
134 896
896 134
134 823
823 119
119 899
899 134
134 922
922 134
134 (
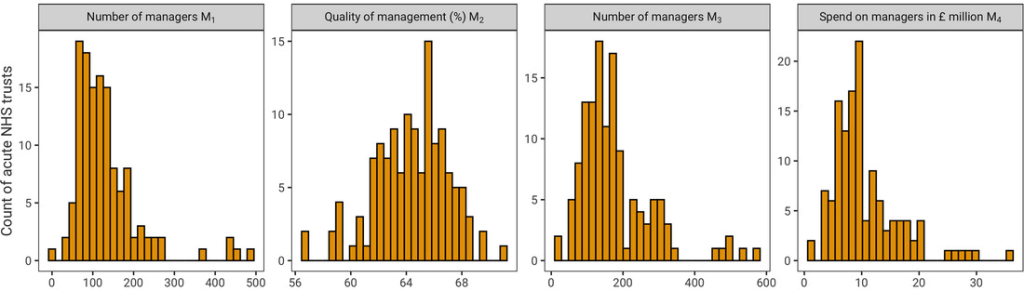
(  (1)Aquí, k indexa los hospitales,
(1)Aquí, k indexa los hospitales,  son los parámetros sobre la cantidad gerencial a estimar, α son los efectos fijos del hospital, λ son los efectos fijos del año, γ son los parámetros relacionados con el tamaño variable en el tiempo y las variables de control de la combinación de casos, y ε es un término de error estándar del modelo de efectos fijos. Esta ecuación se estima para la serie de datos completa, 2012/13 a 2018/19, cuando se utilizan las medidas
son los parámetros sobre la cantidad gerencial a estimar, α son los efectos fijos del hospital, λ son los efectos fijos del año, γ son los parámetros relacionados con el tamaño variable en el tiempo y las variables de control de la combinación de casos, y ε es un término de error estándar del modelo de efectos fijos. Esta ecuación se estima para la serie de datos completa, 2012/13 a 2018/19, cuando se utilizan las medidas  en nuestra especificación empírica para dar cuenta de esta heterogeneidad no observada invariable en el tiempo entre los hospitales. Las pruebas de Hausman indican que los efectos fijos son preferibles a los efectos aleatorios en dos de tres de estas ecuaciones. En el Apéndice
en nuestra especificación empírica para dar cuenta de esta heterogeneidad no observada invariable en el tiempo entre los hospitales. Las pruebas de Hausman indican que los efectos fijos son preferibles a los efectos aleatorios en dos de tres de estas ecuaciones. En el Apéndice  para tener en cuenta los efectos específicos del período y las tendencias temporales generales que afectarían a todos los hospitales de nuestra muestra. Ajustamos los errores estándar de nuestras estimaciones para tener en cuenta la agrupación jerárquica de nuestros datos.
para tener en cuenta los efectos específicos del período y las tendencias temporales generales que afectarían a todos los hospitales de nuestra muestra. Ajustamos los errores estándar de nuestras estimaciones para tener en cuenta la agrupación jerárquica de nuestros datos. (
(  (2)donde todos los términos se especifican como para la ecuación
(2)donde todos los términos se especifican como para la ecuación  siendo los parámetros de entrada de gestión a estimar. Como anteriormente, usamos las pruebas de Hausman para validar nuestra elección de efectos fijos, prefiriéndolos a los efectos aleatorios en 18 de las 20 ecuaciones. Para completar, informamos las especificaciones de variables dependientes rezagadas y de efectos aleatorios agrupados entre sí como comprobaciones de solidez en el Apéndice
siendo los parámetros de entrada de gestión a estimar. Como anteriormente, usamos las pruebas de Hausman para validar nuestra elección de efectos fijos, prefiriéndolos a los efectos aleatorios en 18 de las 20 ecuaciones. Para completar, informamos las especificaciones de variables dependientes rezagadas y de efectos aleatorios agrupados entre sí como comprobaciones de solidez en el Apéndice 



 ;
;  ;
;  .
.




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}